The weak classifier that we consider for the AdaBoost procedure when we’re doing face detections are the Haar features.
They are rectangular features that’s divided in certain black areas and certain white areas.
Each feature is located in a subregion of a subwindow of the image, and they are applied many times modifying the size, the shape and the position inside the sub-window, this for each sub-window of the image.
The value returned by the system for a certain Haar feature is the difference between number of pixels that fall in the white area and the ones that fall in the black area.
We can establish a threshold for this value, so that it will return a yes or not according to the presence of the pattern that we’re trying to find.
The number of possible Haar features for a sub-window is very large (~180.000 for 24x24 window), and this could be a problem for a computational point of view. The computational load can be lowered by using Integral images.
The training involve trying all the possible Haars features on all the examples with all the possible thresholds. The computational complexity, without optimizations, is very high.
Computing Haar features using Integral images
A way to improve the computational complexity is by computing the integral image beforehand, and then use that image to compute the difference bewteen the black and white areas.
An integral image is an image in where the pixel at position has as the value the sum of all the pixels with a and . This region represent the rectangle from the top left of the image to the current pixel.
Formally:
This is a great idea because when we slide the Haar feature rectangle, there are some pixels on the images on which the sum is computed over and over again. This is an useless computation to repeat since the image is always the same.
The AdaBoost learning algorithm is here used both to select a small set of features and to train the classifier. Since there are more than 180.000 reactangle features with every image sub-window, even with the integral images optimization, calculating every feature would be too expensive.
An good classifier is a combination of a very small set of the features, the challenge is to find the best ones.
It’s possible to have a weak classifier , consisting of a feature a threshold and a parity , that can determine the optimal threshold function for each feature, in order to misclassify the least number of examples.
The Attentional Cascade
A series of classifier are applied to every sub-window. The order of the classifiers is important since the first is more general and towards the end they become more and more specific.
Every classifier outputs a True/False result. If a classifier outputs a True value for a certain sub-window, then the sub-window is given in input to another classifier. If one of the classifier in the cascade outputs a False, then the sub-window is rejected.
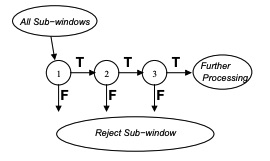
Every classifier is trained with AdaBoost, and the threshold is adjusted in order to have the least false negatives as possible.
How to train the cascade classifier
It’s possible to adjust the weak learner threshold in order to minimise the false negatives. Each classifier is trained on the false positives of the previous stage.

Another approach to localize faces is to use Deep Leaning with Neural Networks.