Note
This document it’s only available in Italian 🇮🇹 for now
Note
Qua è possibile trovare una lista di HCI - Domande e Risposte per l’esame orale.
Wearable Devices
I wereable devices sono dei device che vengono indossati, il che li rende portabili, indossabili ed impiantabili nel corpo umano. Visto che l’uomo ed il device sono intrecciati l’un l’altro, questo porta l’interazione a richiedere molta poca attenzione. Molti wearable devices infatti non richiedono l’accensione o lo spegnimento (constancy - constanza), e raccolgono dati ed effettuano azioni spesso in maniera automatica.
Sono device programmabili dall’utente, che utilizzano algoritmi avanzati e che raccolgono una grande quantità di dati.
L’uomo viene usato come feedback per la macchina, e la macchina come feedback all’uomo, quindi c’è questo loop.
I wereable, come anche i dispositivi più tradizionali (smartphones) possono interrompere l’attività della persona. L’interruzione viene classificata a seconda in varie categorie:
- Immediate: forzano l’utente a cambiare attività ed a prestare attenzione. Un esempio sono la notifica di un allarme in casa.
- Negoziate: notificano l’utente senza distoglierlo dalla sua attività, come ad esempio una notifica di un’app di messagistica. L’utente può guardare la notifica e reagire in futuro.
- Programmate: notificano l’utente periodicamente. Un esempio è la sveglia.
- Mediate: sono notifiche che vengono inviate a seconda del contesto in cui l’utente si trova.
I primi tipi di wearables, risalenti dagli anni 1600, erano:
- Abaco su anello, il quale permetteva di effettuare semplici operazioni matematiche (1600);
- Orologio da polso (1800);
- Timing-device nella scarpa i modo da barare nel gioco della roulette (1960);
- Calcolatrice elettronica su orologio da polso (1970).
I wearables sono dotati di sensori ed attuatori. I primi acquisiscono dati relativi all’ambiente, gli altri effettuano delle azioni a componenti meccaniche a seconda dei dati inviati dai sensori.
Questi dispositivi sono spesso dotati di comunicazione WiFi e Bluetooth.
L’interazione avviene senza mouse e tastiera, ma spesso lo schermo è touch, ed in più l’utente può effettuare delle gestures con il polso (in caso di smartwatch o smart bracelet), oppure coprire l’intero schermo con il palmo.
Il fattore chiave dell’interazione è anche il contesto in cui l’utente si trova. Quindi alcune azioni non potranno essere effettuate se l’utente si trova in una certa situazione, ad esempio agitare molto il polso in caso si è in un meeting. Questo tipo di interazioni si chiamano eyes-free, visto che spesso non necessitano di guardare il dispositivo.
I casi d’uso di questo tipo di dispositivi sono:
- Monitoraggio dell’attività fisica
- Monitoraggio del sonno
- Realtà virtuale ed Aumentata
- Scopi medici
Alcuni contro di questi dispositivi sono:
- A lungo andare, possono essere scomodi da indossare;
- Possono causare troppe interruzioni, se queste non sono ben gestite dall’utente.
Internet of Things
Per IoT si intende quella classe di oggetti che hanno al loro interno un computer, e che sono differenti da computer tradizionali o smartphones. Sono device connessi, non per forza ad Internet, ma connessi ad un qualche dispositivo che poi ha accesso ad internet.
Un esempio di tale dispositivi sono:
- Elettrodomestici Smart, i quali solitamente dispongono di un’applicazione che permette di vedere delle statistiche, di controllarli o di programmare azioni anche a distanza. Questi solitamente si connettono direttamente ad Internet tramite il WiFi casalingho.
- Telepass: non è connesso direttamente ad Internet, però si connette al dispositivo del casello per trasferire dei dati.
- Airtag: si connette ad ogni prodotto Apple nelle vicinanze, il quale è poi connesso ad Internet, per aggiornare la sua posizione.
La UI su questo tipo di dispositivo solitamente è limitata, a causa dello spazio disponibile e del costo.
Per quanto riguarda i modi in cui dare un input ad un dispositivo IoT:
- Controlli fisici: sono comodi perchè sono tattili e possono essere quindi riconosciuti attraverso il tatto. La loro posizione è fissa e quindi richiedono poca attenzione da parte dell’utente, se questo è abituato ad usarli. Ovviamente non possono essere aggiornati e spostati in maniera semplice.
- Bottoni
- Manopole: possono essere con rotazione finita o infinita, e possono essere discreti o continui.
- Switches: un bottone non rimane nello stesso stato in cui viene premuto, mentre uno switch si. Uno switch è utile per mostrare lo stato del sistema, ma questo può non essere accurato. Pensa a quando ci sono due switch che controllano la stessa luce.
- Schermi Touch: fanno in realtà parte dei controlli fisici, ma tra i pro hanno il fatto che possono mostrare diverse interfacce a seconda dello stato, e la UI può essere aggiornata tramite software. I contro sono che richiedeono grande attenzione dell’utente, visto che questo deve guardare lo schermo, ed il dito per cliccare su un bottone digitale.
- UI Tangibili: muovere oggetti in modo da dare un input al sistema. Un esempio è un tipo di svegla che può essere ruotata per cambiare le informazioni visualizzate sullo schermo. L’interazione tangibile può essere anche una forma di output, visto che la posizione dell’oggetto stesso descrive lo stato del sistema.
- Riconoscimento vocale: comodo perchè hand-free ed eye-free, ma non può essere usato in ogni contesto, visto che ci sono delle situazioni in cui non è appropriato. Come pro ha anche che richiede poco spazio e poca capacità computazionale, visto che localmente solo l’audio viene catturato, e la computazione viene effettuata sul Cloud.
- Gestures: permettono di interagire col sistema tramite movimenti del corpo.
- Contesto: il contesto in cui l’utente si trova in quel momento può essere un input al sistema.
- Pensieri: ancora in fase di sviluppo, permettono di controllare il sistema tramite le onde cerebrali.
- Battito cardiaco e fattori corporei: permettono di determinare il sonno e altri fattori come la salute mentale.
Oltre agli input, i dispositivi IoT devono spesso dare un feedback all’utente. Le modalità di output sono le seguenti:
- LED: l’informazione viene trasmessa attraverso il colore dei led, i pattern o il pattern del lampeggiamento del led. È comodo perchè poco costoso, anche in termini di energia utilizzata, e richiede molto poco spazio. Richiede poca attenzione da parte dell’utente, ma la quantità di informazione che si può trasmettere è molto limitata.
- Schermi: a seconda di quanta informazione deve essere trasmessa, si posso usare diverse tipologie di schemi. I 7-segment displays vengono usati nelle sveglie, visto che sono poco costosi e riesco a rappresentare ogni numero con un pattern di 7 segmenti. Negli e-book vengono usati gli schermi e-ink, che sono meno costosi in termini di energia, e non emettono luce, quindi non producono nessun danno agli occhi. Per le informazioni più complesse bisogna far affidamento a schermi tradizionali, in bianco e nero o a colori. In generale prima di progettare un dispositivo bisogna chiedersi: “questa feature può funzionare anche senza un display?”. (Altrimenti si incorre nel feature creep, in cui il prodotto viene riempito di funzionalità, la quale abbondanza rovina l’esperienza.)
- Suoni e Text to Speech: i suoni ed il parlato possono essere un altro mezzo di trasmissione delle informazioni. Come pro abbiamo il fatto che un testo parlato può anche includere delle emozioni, così come i suoni. Inoltre questo rende possibile un’interazione con meno attenzione, visto che non bisogna ne toccare ne guardare il dispositivo. Come contro abbiamo il fatto che non sempre si è in un contesto in cui è appropriato emettere voci e suoni.
- Vibrazioni, force feedback: le vibrazioni possono essere utilizzate come feedback per far capire all’utente che una certa azione è stata svolta.
- Altri (Odori e Temperatura): il sistema può generare degli odori o cambiare temperatura per trasmettere delle informazioni.
Molti di questi dispositivi inoltre possiede delle batterie, quindi bisogna anche limitare il consumo dell’energia al minimo. Una tecnica è l’attivazione ad intermittenza, in modo da scambiare dati con una certa frequenza, limitando il periodo di accensione. Questo può portare il sistema, soprattutto se fatto da più interfacce su più dispositivi, a non essere sincronizzato. Ad esempio se cambiamo la temperatura del condizionatore dall’applicazione, e lo schermo del condizionatore di aggiorna dopo qualche minuto.
Quando una persona si connette ad internet, si aspetta di attendere un breve periodo di caricamento. Quando invece interagisce con oggetti reali, si aspetta che l’interazione sia istantanea. Se stiamo parlando di un oggetto smart, e quindi connesso ad internet, l’interazione potrebbe comunque richiedere del tempo, e quindi l’utente è frustrato.
Visto che i dispositivi sono connessi ad Internet, se questo smettesse di funzionare, si perderebbero molte funzionalità.
I dispositivi smart permettono di svolgere delle azioni su dispositivi fisici da remoto, o programmarli per essere eseguite automaticamente in un periodo futuro. Visto che questo aggiunge dell’astrazione (l’utente non interagisce fisicamente con l’oggetto) c’è bisogno di un feedback che faccia capire che l’azione è stata compiuta.
Visto che i dispositivi IoT sono prodotti da vari produttori differenti, c’è bisogno che questi siano compatibili tra di loro il più possibile, visto che un utente preferisce acquistare prodotti che si integrano bene tra di loro.
I dispositivi nell’IoT si basano su una serie di principi, uno dei quali è l’iterusabilità. Questo vuol dire che la UX si basa sull’usabilità di tutte le parti del sistema, e quindi bisogna progettare tutte le varie parti (dispositivo, applicazione mobile, applicaizone web, telecomando) in parallelo in modo da migliorare l’interusabilità. L’interusabilità viene calcolata come la quantità di QUALCOSA + efficienza e soddisfazione.
Interusability: IoT User Experience Beyond The Level Of A Single Device | SpinDance
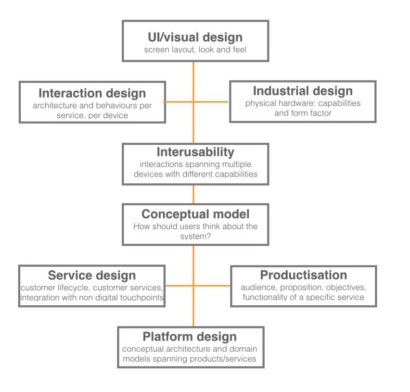
Questo è lo stack di progettazione per dispositivi IoT, analizziamo le singole componenti:
- UI Design: si incentra sulla progettazione dell’interfaccia, principalmente del layout, dell’estetica e delle sensazioni che questa provoca;
- Interaction Design: analizza l’intrazione che l’utente ha con il dispositivo.
- Interusability: vedi sopra.
- Service Design: si incentra sul capire qual è il ciclo di vita dell’utente, analizzando gli aggiornamenti futuri e le nuove funzionalità, l’assistenza clienti, l’esperienza nello Store ecc.
- Conceptual Model (o Mental Model): è il modello che l’utente ha del sistema, ovvero un qualcosa di più astratto che permette all’utente di capire come il sistema funziona, evitando i dettagli tecnici.
- Productisation: analizza le funzionalità, i servizi e gli obiettivi che rendono speciale un tipo di prodotto, in modo da dare importanza al valore che il sistema aggiunge.
- Platform Design: si focalizza sul framework software che permette agli altri sviluppatori di utilizzare ed estendere il sistema, in modo da gestire gli utenti, le azioni ed i dati.
Beacons
I beacons sono dei dispositivi che utilizzano la tecnologia Bluetooth Low Energy (BLE) introdotta nella versione 4.0 del protocollo Bluetooth. Questa tecnologia permette la comunicazione ad una distanza fino a 90 metri, ed opera nella banda di frequenza 2.4Ghz.
Con il Bluetooth 5.0 tale portata è stata quadruplicata, la velocità raddoppiata nonchè un auemnto di otto volte della capacità di trasmissione dei dati rispetto alla versione precedente.
How Bluetooth Low Energy Works: Advertisements (Part 1)
I beacons sfruttano la funzione BLE advertising, che consente a tali dispositivi, che operano come broadcasters, di trasmettere un ID e di mostrare dei servizi disponibili agli observers. Possono essere trasmessi anche altri dati, affinchè questi siano solo pochi bytes. Un esempio di ulteriori dati possono essere la distanza dal beacon all’observer. **Ciò permette agli observer, che solitamente sono smartphones, di ricevere il segnale quando sono vicini ad un certo beacon, e, a seconda dell’ID del beacon, effettuare determinate azioni.
I beacon fanno sia da broadcasters (advertisers), che da peripheral. Un dispositivo central può connettersi al beacon per leggere e scrivere dati. Solitamente questo dispositivo viene utilizzato per configurare o aggiornare il dispositivo beacon.
In generale:
- Un Broadcaster è un dispositivo che trasmette pacchetti tramite BLE per fornire informazioni riguardanti la presenza e l’identità ai dispositivi nelle vicinanze. Tale azione viene chiamata advertising, per questo ci si può riferire a tale ruolo anche come advertiser.
- Un peripheral è in generale un dispositivo che si connette ad un dispositivo central tramite BLE.
- L’observer è il dispositivo che ascolta i pacchetti che vengono inviati dal Broadcaster, e che agisce di conseguenza.
- Il Central è un dispositivo in grado di connettersi al Broadcaster e di leggere e scrivere i dati. Questo dispositivo viene solitamente utilizzato per configurare il beacon.
Visto che i beacon trasmettono una minima quantità di dati, la batteria ha una lunga durata, solitamente tra i 3 e i 5 anni.
Ci sono due differenti tipi di protocolli beacon:
- iBeacon, per Apple. Un dispositivo iOS può ascoltare fino a 20 beacon simultaneamente. Quando il dispositivo riceve un segnale di un beacon vicino, il sistema operativo manda un segnale all’applicazione interessata, la quale può eseguire delle azioni.
- Eddystone, sviluppato da Google, è supportato sia su Android che iOS.
Visto che il sistema operativo si occupa di gestire l’ascolto dei beacon nelle vicinanze, questo funzionerà anche se lo schermo è spento e l’applicazione interessata è chiusa.
Un applicazione può sottoscriversi ad una regione, che è un’area in cui il segnale del beacon si propaga. Un azione può essere svolta all’entrata o all’uscita di una certa regione. Questa funzionalità usa molta poca batteria dello smartphone.
Solamente quando l’applicazione è aperta ed in uso, è possibile effettuare ranging, ovvero azionare dei comportamenti a seconda della prossimità del beacon. Questo può essere svolto solamente in foreground dato l’alto consumo della batteria.
Il ranging è utile per tracciare la posizione del dispositivo indoor, dove il segnale GPS non è affidabile. Un ranging accurato viene effettuato tramite triangolazione, quindi vengono posizionati tre beacon all’interno di un’area, e l’incrocio delle tre circonferenze con raggio che va dal beacon al dispositivo permettono di localizzare, con un errore nell’ordine dei metri, il dispositivo.
UWB
L’Ultra Wide Band è un tecnologia di trasmissione dati radio ad alta frequenza (più di 500Mhz), che utilizza una bassa quantità di energia. Può sostituire qualsiasi applicazione in cui sono presenti dei beacon, però il dispositivo è più costoso.
Attualmente viene usato per collezionara dati da sensori e per una precisa localizzazione, sopprattutto negli ambienti indoor. È utilizzata negli AirTag.
Il supporto all’UWB è stato introdotto nei dispositivi di fascia alta a partire dal 2019.
L’UWB permette di trasferire una grande quantità di dati, senza causare interferenze con altri segnali. Un dispositivo può captare la presenza di un dispositivo UWB, e la sua posizione, con un errore nell’ordine dei centimetri, misurando il ToF (Time of Flight) della trasmissione, che sarebbe il tempo che il segnale ci mette a raggiungere il beacon ed a tornare indietro.
Chatbots
Un chatbot è un programma che interagisce con l’utente attraverso una interfaccia a chat, in cui possono essere scambiati dei messaggi. Costruire un chatbot è complicato in quanto devono essere usate conoscenze di NLP.
I primi chatbot erano “hard-coded”, e quindi l’utente aveva un limitato insieme di frasi da poter dire al chatbot, e questo rispondeva in maniera programmata.
Al giorno d’oggi, soprattutto dopo l’avvento dei Large Language Models (LLM) come GPT, i chatbot vengono usati in molte situazioni, ad esempio nell’assistenza in modo da ridurre il numero di operatori umani, e quindi ridurre i costi.
I chatbot vengono anche usati su applicazioni come Telegram e Discord, visto che un utente scarica tali applicazioni per parlare con delle persone, ma poi può parlare anche con dei bot, senza scaricare un’applicazione apposta. In queste applicazioni spesso i bot sono un mix di chatbot e UI standard, visto che sono dotati di una serie di comandi che possono essere inseriti o cliccati. Nelle applicazioni di messaggistica, i chatbot vengono anche inseriti in gruppi per compiere delle azioni automatiche, come rilevare la spam e bloccare utenti malevoli, oppure effettuare sondaggi, leggendo i messaggi degli utenti nel gruppo.
Il problema con i chatbot più antichi è il fatto che la conversazione non mantiene uno stato, quindi non era possibile effettuare delle “follow up questions” o semplicemente continuare il discorso. Con l’avvento dei LLM questo è un problema che ormai è stato risolto, visto che tali modelli estremamente complessi hanno capacità di mantenere un contesto.
Quando avviene un errore, il chatbot dovrebbe rispondere in maniera umana, oltre che comunicare che tipo di errore si è verificato ed eventualmente perchè, così l’utente può capire e si sente meno frustrato.
In caso il chatbot ha un interazione a comandi più “hard-coded”, bisognerebbe dare dei consigli all’utente per fargli capire quali sono i comandi accettati.
Un chatbot più avanzato, che passerebbe anche il Turing Test, dovrebbe far sapere all’utente che questo sta parlando con un bot e non con un umano.
Voice User Interface
Una Voice User Interface è l’estensione di un chatbot al campo eslusivamente vocale. Questa estensione ha delle limitazioni, come la lunghezza delle frasi, che nel chatbot può essere molto più estesa mentre in una VUI deve essere molto più concentrata.
Il dispositivo che integra una VUI, e che è dotato di microfoni di input e altoparlanti per l’output (ed eventualmente anche di uno schermo) viene chiamato un Voice Command Device.
Le VUI hanno parecchi problemi che sono difficili da risolvere:
- Barge-In, ovvero la possibilità di interrompere l’assistente vocale mentre sta parlando, per aggiungere un qualcosa, per stopparlo o per cambiare argomento. In generale il capire quando è il turno dell’utente e quando è quello della VUI è complicato e può portare alla confusione;
- Identificare chi sta parlando tra una serie di persone;
- Come capire cosa è possibile chiedere alla VUI, e cosa invece porterebbe ad un errore perchè non è stato implementato;
- Capire se il sistema ha effettivamente compreso la richiesta o no.
- Recall invece di Recognition: l’utente deve ricordare tutti i possibili comandi, invece di selezionarli da una lista.
- L’attesa tra la richiesta e la risposta può portare la persona a pensare che la VUI non abbia capito, e quindi alla confusione ed al ripetere la richiesta, il che causerebbe degli errori nella VUI.
In generale, le Voice User Interfaces fanno sentire l’utente meno in controllo rispetto alle UI tradizionali, per questo dovrebbero essere molto minimali, in modo da poter eseguire una funzionalità nella maniera più semplice possibile, senza far confondere l’utente.
L’interazione con le VUI possono essere di tre tipi:
- Command and Control: interazione one-way, l’utente utilizza la voce per dare comandi al sistema. L’output è tradizionale.
- L’interazione one-way opposta, in cui l’utente trasmette l’input in maniera tradizionale, e l’output è sottoforma di voce.
- Spoken Dialogue System: interazione two-way in cui avviene un dialogo tra l’uomo e la macchina, tutti e due tramite la voce.
Una tradizionale pipeline per la gestione di un dialogo tra uomo e una VUI consiste nelle seguenti fasi:
- Riconoscere che l’utente sta interpellando l’assistente vocale;
- Capire chi, tra una serie di utenti, sta facendo la richiesta;
- Riconoscere cosa l’utente sta dicendo attraverso un sistema di Automatic Speech Recognition;
- Interpretare la richiesta dell’utente tramite un sistema di Natural Language Understanding;
- Seleziona l’azione ottimale a seconda dell’intento dell’utente, considerando eventualmente anche il contesto attuale;
- Generare una risposta in linguaggio naturale;
- Trasformare la risposta da testo al parlato tramite un sistema di Text to Speech.
Progettare una VUI richiede molteplici competenze, come informatiche, linguistiche e psicologiche.
Così come in tutti gli altri sistemi, anche nelle VUI ci sono gli utenti esperti, i quali hanno più dimestichezza con il sistema. Per questo motivo bisogna inserire delle scorciatoie in modo che questi possano effettuare delle azioni in maniera più efficiente. Un esempio è quella di inserire tutti i parametri in una sola frase invece che essere guidati da una serie di domande e risposte.
Haptic Interaction
L’interazione tattile (haptic) non è solo un modo per dare input al sistema, ma anche per ricevere un feedback. È possibile ad esempio dare l’input alla macchina toccando degli oggetti virtuali, i quali faranno scattare un trigger tattile che farà capire all’utente che ha effettivamente toccato quell’oggetto.
L’interazione tattile è utile quando non si può utilizzare il feedback visivo, magari perchè in situazioni particolari, come la guida, o magari per condizioni di cecità. Tramite l’interazione tattile, l’utente può percepire la forma di un tasto virtuale, o capire l’azione compiuta solamente dal feedback tattile. Per esempio Apple Watch permette di capire l’ora solo tramite le vibrazioni, se ci si trova in una situazione in cui non è adeguato guardare l’orologio.
L’interazione tattile si basa su differenti capacità umane:
- Percezione tattile: l’abilità di percepire cose a contatto con la pelle.
- Senso cinestetico (Kinesthetic Sense): l’abilità di capire dove solo le parti del corpo senza effettivamente guardarle.
- Percezione cinestetica (Kinesthetic Perception): dipende dal senso cinestetico, ed è l’abilità di capire dove sono le parti del corpo anche senza il senso tattile (si pensi quando vengono usati degli anestetici).
- Percezione tattile passiva (Passive Haptic Perception): la capacità di capire il posizionalemnto del corpo dalle informazioni tattili. Passivo perchè le informazioni vengono dal mondo esterno e il cervello le elabora soltanto.
- Copia dell’Efferenza (Efference Copy): consiste nella predizione del movimento e delle azioni da questo causate. Questo è utile perchè l’effettivo movimento può essere aggiustato a seconda della predizione.
La percezione visiva è più veloce di quella tattile, ma in alcuni casi la percezione tattile può essere più affidabile, ad esempio per capire la texture di un materiale. Ovviamente per altri casi la percezione visiva può essere più affidabile.
In generale, i simboli rialzati sono più facili da distinguere dei simboli incisi.
Nella storia, sono stati fatti dei tentativi per dei display tattili, che utilizzavano le vibrazioni e delle parti scorrevoli per simulare le texture. In generale ci sono vari modi per ottenere un feedback tattile, dalla vibrazione, all’abrasione della pelle, all’uso di corrente elettrica.
Ci sono varie limitazione nell’interazione tattile, tra cui:
- Risoluzione spaziale: la distanza minima per cui due punti vengono percepiti come uno solo.
- Risoluzione temporale: il tempo affinchè la persona percepisca l’oggetto tramite il tatto, solitamente tra 2 a 40ms.
- Interazione tra stimoli ampiamente distanziati: si potrebbe verificare l’evento del “punto fantasma” quando due punti vengono presentati a tutte e due le mani.
- Attenzione limitata: l’incapacità di concentrarsi quando c’è un ecesso di informazioni.
In un dispositivo, il Degree of Freedom (DOF) è il numero di assi in cui questo può essere mosso. Un volante ad esempio ha un solo DOF, visto che può essere mosso solo a destra e sinistra, mentre una penna ha 2 DOF, in caso di pressione anche 3 DOF.
Esistono anche dispositivi con 6 DOF (più dei 3 assi spaziali), visto che questi possono essere mossi nel mondo tridimensionale, ma si può arrivare in un punto mediante strade diffrerenti. Questo è possibile perchè ci sono due parti che entrambe hanno 3 DOF (two rotating arms). In generale, più DOF significa più facilità nel muovere l’oggetto.
Per Haptic Rendering si intende l’effettuare una forza opposta quando l’oggetto virtuale viene toccato, in maniera da dare l’illusione della solidità.
Questo tipo di oggetti dovrebbe apparire invisibile all’utente, in modo da dare l’illusione che l’oggetto che effettua il feedback tattile (come dei guanti nella realtà virutale) non sia presente affatto.
Il loop tattile ha una frequenza maggiore del loop visivo (1000Hz contro i 60Hz), visto che la tattilità ha una risoluzione temporale maggiore.
Tangible Interaction
Per interazione tangibile si intende quel tipo di interazione in cui è possibile dare un input al sistema muovendo degli oggetti reali.
Esempi di interazione tangibile sono:
- Prendere in mano il telefono da una superfice per attivare lo schermo;
- Bussare sullo schermo per fare uno screenshot;
- Mettere il telefono a faccia in giù su una superficie per attivare la modalità “non disturbare”.
Un altro esempio più sperimentale è la Marble Answering Machine, ovvero un prototipo di segreteria telefonica tangibile, in cui i messaggi erano modellati da delle biglie, e che quindi potevano essere sentire semplicemente ponendo la biglia relativa sulla macchina.
Un altro esempio di TUI sono le Graspable Interfaces, le quali permettono di interagire con oggetti fisici che vengono posti sopra lo schermo, in modo da interagire con le forme digitali che vengono visualizzate sullo schermo.
Il pro principale delle TUI è la loro intuitività, in quanto basta manipolare oggetti fisici per interagire con il sistema. Il contro è che questa interazione richiede spazio e tecnologie particolari.
Si definisce come affordance le proprietà di un oggetto che suggerisce come questo può essere usato. Ad esempio un pomello suggerisce che questo può essere girato, un bottone di essere premuto ecc.
Gli oggetti tangibili possiedono un’affordance reale, quelli virtuali un’affordance percepita.
È possibile combinare la realtà aumentata ad una interfaccia tangibile. Un esempio è un libro che mostra in realtà aumentata gli animali che vengono mostrati sulla pagina. Quando si gira pagina (interazione tangibile), cambia anche il relativo animale mostrato.
Le TUI utilizzano il modell MCR (Model-Control-Representation), in cui gli oggetti tangibili rappresentano lo stato del sistema, quindi anche se il sistema viene spento, l’utente è ancora in grado di percepire lo stato del sistema (totale o parziale). Il modello è rappresentato dai dati digitali, mentre il controllo avviene con gli oggetti reali.
Possiamo classificare le TUI in tre categorie:
- Superfici Interattive, come tangible bits.
- Assemblamento Costruttivo, come sandscape.
- Token + Vincoli, come la Marble Answering Machine
Il contro principale delle TUI è il fatto che una funzione di undo non può essere implementata, e che lo stato precedente ad un’azione va ricordato, altrimenti questo viene perso. Inoltre non esiste il concetto di macro per facilitare una serie di azioni svolta frequentemente.
Ogni TUI viene progettata per un singolo scopo, e difficilmente può essere espansa a più scopi. Possono inoltre causare fatica con un utilizzo prolungato.
Le tecnologie principali per lo sviluppo di TUI sono:
- RFID, per l’identificazione di oggetti sulla superfice. Gli RFID sono comodi perchè non richiedono una batteria.
- Computer Vision, permettono non solo di capire se un oggetto è presente o meno, o di identificare tale oggetto, ma anche di capire la sua forma, il colore, la posizione esatta, la forma e l’orientamento.
- Microcontrollori, sensori ed attuatori.
Gestural Interaction
Per interazione gestuale si intende quel tipo di interazione con il sistema attraverso movimenti con il corpo. Esistono due tipi di gestures:
- Touch Gestures: effettuate su una superfice touch, permettono di interagire in maniera più intuitiva con il sistema. Un esempio di queste interazioni sono lo swipe o il pinch.
- Touchless Gestures: vengono effettuate nello spazio tridimensionale, senza toccare nessun dispositivo. Vengono principalmente usate in VR e AR. Nella restante parte, ci focalizzeremo su questo tipo di Gestures.
Le gestures possono essere catturate attraverso diversi sensori, come accelerometri, giroscopi (ad esempio per il wake up di uno smartwatch quando si gira il polso). camere con sistemi di computer vision (come il Kinect), camere ad infrarossi, scanner laser e camere stereoscopiche.
I gesti possono essere catturati con o senza la consapevolezza dell’utente.
- Se l’utente non è consapevole, i gesti saranno naturali;
- Se l’utente è consapevole, i gesti sono influenzati dal fatto che cercherà di renderli più comprensibili dal sistema.
A volte interagire con un sistema attraverso dei gesti potrebbe non essere socialmente accettabile, questo dipende soprattutto in che contesto ci si trova.
Un altro fattore da considerare è l’effetto Gorilla Arm, in cui l’interazione porta ad un affaticamento nel lungo periodo.
Per quanto riguarda la realtà virtuale, questa presenta vari problemi. Uno di dato dal fatto che lo spazio virtuale è molto più grande dello spazio reale in cui la persone è immersa, quindi non si può liberamente camminare nello spazio reale, ma bisogna teletrasportarsi utilizzando appositi comandi nello spazio virtuale, il che rende l’esperienza meno realistica.
Definiamo come:
- Fedeltà dell’interazione (Interaction Fidelity): il grado con cui le azioni all’interno della UI corrispondono a quelle effettuate nel mondo reale. Ad esempio quanto devo muovere il braccio per effettuare uno spostamento nel mondo virtuale. Maggiore la fedeltà, più realistica l’interazione.
- Movimenti ipernaturali (Hypernatural Movements): la possibilità di fare movimenti nel mondo virtuale che non sarebbero possibili nel mondo reale. Questo non intacca la fedeltà visto che l’utente è consapevole di star facendo movimenti possibili sono nel mondo virtuale.
Visto che solitamente l’interazione gestuale non è molto affidabile, si possono usare altri dispositivi di input in aiuto, come i joystick nel caso della maggior parte dei visori di realtà virtuale.
Un modo per aumentare l’affidabilità dei gesti è quello di prendere la media nell’intorno di vari punti quando l’utente sta cercando di rimanere fermo, in modo da evitare che il cursore oscilli. Si può anche modificare il raggio control/display, ovvero l’utente deve fare un movimento ampio per muovere di poco il cursore nel mondo virtuale, in modo che questo sia più preciso.
Quando si ha a che fare con le gestures, non è possibile lasciare il cursore da qualche parte come viene effettuato con il mouse, che può rimanere “parcheggiato”.
Zooming Interfaces
Quando si naviga in interfacce classiche, come quelle di una webapp, si fa fatica a capire con quale sequenza di azioni ci si è trovati in una certa pagina. È come se fosse un labirinto.
Una zooming UI è un’interfaccia che si presenta come una tela infinita, con risoluzione infinita, in cui l’utente può fare “zoom out” per vedere la situazione generale, e poi fare “zoom in” per vedere sempre più dettagli.
Un esempio di sistemi che utilizzano questo tipo di interfacce sono Figma, Excalidraw e Google Maps.
Lo zoom imposta una gerarchia, in maniera tale che il sistema possa effettuare delle azioni a seconda del livello di zoom in cui l’interfaccia si trova in quel momento. Ad esempio in google maps quando lo zoom è ridotto vengono caricate delle texture in bassa risoluzione, la quale aumenta quando si effettua uno zoom maggiore.
Il pro delle ZUI è che l’utente può organizzare il contenuto della tela nella maniera preferita, e può vedere il quadro generale, quindi diminuendo la probabilità di perdersi all’interno del contenuto come può avvenire per sistemi complessi con UI tradizionali, visto che qui l’utente si ricorda la posizione attraverso landmarks, ovvero punti di riferimento, invece che attraverso una sequenza di pagine.
HCI nell’automobile
Nel corso degli ultimi anni le automobili sono diventate sempre più smart e connesse. Possiedono CPU, sensori ed attuatori sempre più potenti ed affidabili.
Nelle auto sono presenti diversi sistemi:
- Navigazione ed Intrattenimento;
- Interfacce per il cellulare, in maniera da utilizzare alcune funzionalità del telefono in maniera sicura, senza prestare troppa attenzione;
- HVAC (Heating, Ventilation and Air Conditioning).
La connessione del telefono all’auto porta a dei problemi, ad esempio se nell’auto ci sono più persone, tutte con il bluetooth attivo, quale smartphone dovrebbe connettersi all’auto?
In generale, l’HCI all’interno dell’automobile cerca di ridurre le distrazioni del guidatore. Queste distrazioni possono essere di due tipi:
- Visuali: la persona sta guardando qualche altra cosa;
- Cognitive: la persona sta pensando a qualche altra cosa, e quindi non sarebbe in grado di reagire velocemente ad un evento improvviso.
Ci sono sistemi di sicurezza che consentono all’auto di rilevare un ostacolo sulla strada e di frenare di conseguenza, ma il punto è capire perchè il guidatore era distratto.
Nel contesto della guida, gli schermi touch sono un rischio alla sicurezza. I pulsanti fisici possono distrarre meno, visto che hanno una natura tattile, e la loro posizione non cambia. Per i comandi touch la persona deve vedere dov’è il pulsante, vedere dov’è il dito, cliccare e poi vedere se il contesto è effettivamente cambiato, per capire se l’azione è stata effettivamente presa.
Molte auto hanno dei bottoni fisici sul volante, visto che è quello il posto dove naturalmente risiedono le mani. Questi sono comodi e non distraggono il guidatore. Quando si gira il volante sono difficili da raggiungere, oltre che a capire la loro posizione, ma spesso si può aspettare che il volante sia di nuovo nella posizione corretta per premere un bottone.
In caso di azioni critiche, come fermare il cruise control perchè c’è del traffico improvviso davanti, deve esserci un controllo raggiungibile istantaneamente. Nel caso del cruise control, questo può essere disattivato premendo il pedale del freno.
A volte anche gli input possono distrarre, ad esempio controllare il volume dello stereo. Esistono alcuni sistemi che puntano a ridurre le distrazioni, come l’head up display, che permette di visualizzare alcune informazioni sul cruscotto così da non distogliere lo sguardo dalla strada.
Un modo per mitigare le distrazioni è quello di usare interazioni hand-free, come la voce per l’input e i suoni o la voce per l’output. Il problema è che l’input vocale non è affidabile, e a volte non appropriato (ad esempio se qualcuno sta dormendo).
Le interfacce gesturali a volte possono essere più comode ed affidabili. Il problema principale con queste è che possono essere ambigue, e comunque serve controllare lo stato del sistema per ricevere un feedback sull’avvenimento o meno dell’azione, per capire se la giusta azione è stata compiuta.
Nell’auto esistono un sacco di sistemi di cui l’utente non ha il controllo, e di cui potrebbe anche esserne completamente ignaro, come l’ABS. Per altri invece si vuole avere il controllo, come il parcheggio automatic, a volte il guidatore vuole parcheggiare, a volte magari vuole che l’auto lo faccia per lui.
Context Aware Interaction
Capire il contesto in cui l’utente si trova è essenziale per migliorare l’usabilità del sistema. A seconda del contesto, l’interfaccia potrebbe cambiare automaticamente, o eseguire altre azioni, anche senza l’attenzione dell’utente.
Qualche esempio di sistemi context-aware sono:
- Porte automatiche;
- Cambio automatico tra modalità chiara e scura a seconda dell’ora del giorno o della quantità di luce nell’ambiente circostante;
- Modalità “auto” automatica nelle applicazioni di riproduzione musicale quando si è connessi ad un automobile;
- Riposta automatica ai messaggi ed alle chiamate quando si sta guidando.
- Sistema di ABS nelle auto. Questo monitora costantemente il bloccaggio delle ruote e, quando questo avviene, rilascia a intermittenza i freni in modo da evitare che le ruote si blocchino.
Per rendere tutto questo possibile, è necessario un algoritmo (spesso implementato tramite ML) che permetta di classificare il contesto a seconda dei dati catturati da uno o più sensori.
Nel caso degli smarthone, tale algoritmo è implementato nel sistema operativo, e permette di catturare dei contesti comuni, ad esempio quando l’utente sta camminando, correndo, dormendo ecc. Tale contesto può essere poi usato dall’applicazione interessata per effettuare le azioni necessarie.
Nel 1991 qualcuno diceva che la tecnologia dovrebbe essere trasparente all’umano, ed i sistemi context-aware permettono proprio questo, visto che agiscono in maniera completamente trasparente all’utente a seconda del contesto in cui questo si trova.
A volte il contesto percepito dal sistema è differente dal contesto percepito dalla persona. Ad esempio per quanto riguarda le luci ad accensione automatica con un sensore di movimento, per il sistema il contesto è “si è verificato un movimento”, mentre per la persona è “sono all’interno della stanza”. Questo causa una peggiore esperienza utente, visto che in mancanza del movimento la luce verrà spenta, anche se la persona si trova ancora all’interno della stanza.
Il contesto umano è basato su ricordi ed esperienza, mentre quello percepito dal sistema è basato su sensori ed algoritmi. Questo fenomeno si chiama Awareness mismatch.
A volte un sistema dovrebbe poter dare dei consigli all’utente circa qual è il contesto rilevato, in maniera tale che l’utente possa capire cosa c’è che non va quando c’è un mismatch.
Il contesto può essere utilizzato anche per creare dei contenuti automatici, ad esempio mandare un messaggio ad un contatto SOS quando viene rilevata una caduta o un incidente d’auto.
Il contesto in generale è molto utile per anticipare ciò che l’utente vuole, il che è un’operazione difficile.