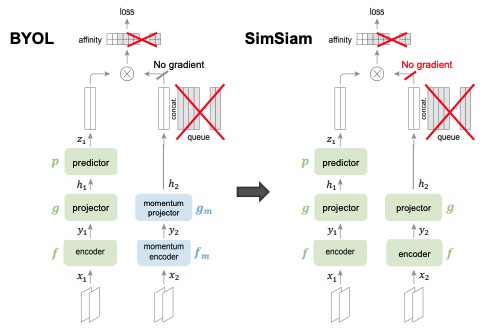
SimSiam is a modification of the BYOL architecture, where they replace the momentum projector and the momentum encoder with the same projector and encoder from the left branch, but add a stop gradient technique (you don’t back propagate on the right branch).
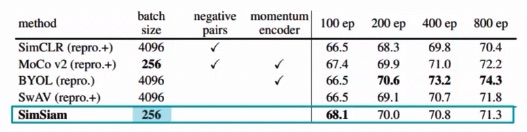
SimSiam has better performances for the first epochs of training, while is outperformed by BYOL in the long run (over 200 epochs).