Dense Captioning
Dense captioning means doing object detection and then do captioning for each bounding box, describing each thing that happens in the image using the natural language.
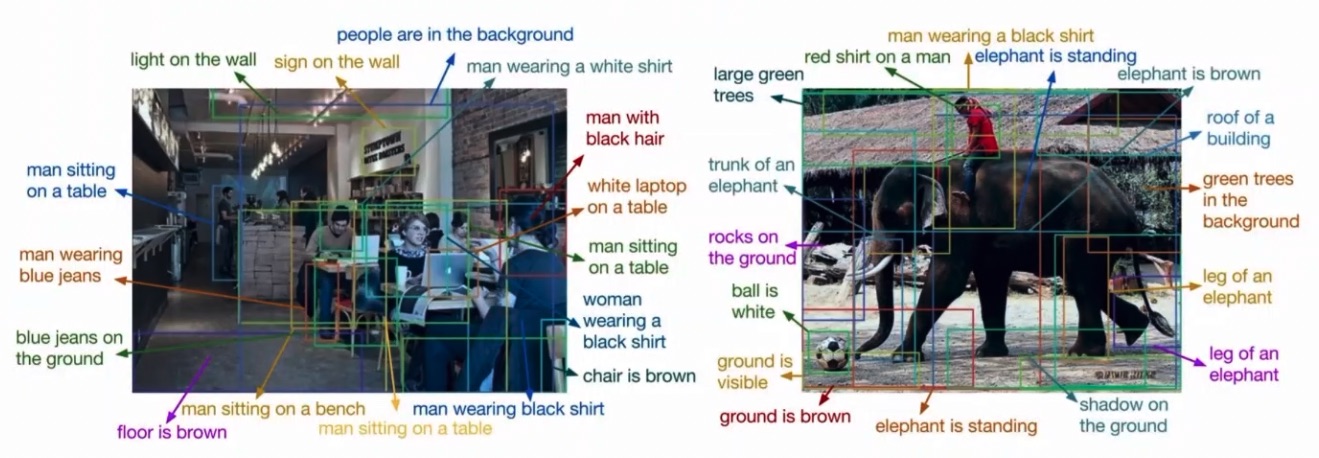
This was also applied later on on video.

3D Object Detection
3D object recognition is way harder than 2D detection, since a bounding box has many more coordinates (yaw, pitch, roll and others.).
There are a lot of different ideas on how to do 3D object detection.
- An idea is to find region proposals in the 3D space, then project them into the 2D space and input them into a simple Faster R-CNN. Since the proposals are 3D boxes, they should be more accurate.
- The opposite idea is to get the proposal in the 2D space and do detection in the 3D space.
3D Shape Prediction
Representing 3D objects
When we’re dealing with 3D objects, we need a way of representing them inside of a computer. Differently from images, where basically the only representation is a grid of pixels, we have different ways of encoding a 3D object:
- Voxels ( binary cube): we represent an object as a D$$^ 3 dimensional cube, in which each discrete piece is if the object is not part of it, or otherwise. This is not the most optimal way, since we’re using memory even for the non occupied space (the s).
- Point-cloud ( floats): Similar to the voxels, here we have a list of points, each one with a set of coordinates to determine the location in the space. The issue with point-cloud is that the points do not have a volume, so if I want to shoot a ray to see where will it intercept with the surface of the object, the ray will go trough, since there is no actual surface.
- Mesh ( floats and 3 integers): A mesh is similar to a point cloud, with the addition of a small triangle that defines the surface on a specific point.
Mesh R-CNN
In recent years that has been research to go from 2D detection, to instance segmentation to 3D shape prediction (in Mesh R-CNN it’s done by refining voxels into a mesh).