A multibiometric system is a very effective approach to improve the robustness of the biometric system.
Most of the present systems are based on a single biometric trait, which make the system much easier to spoof than if it was based on more biometric traits, because the attacker should attack each biometric sensor.
It’s a good idea to use more that one biometric traits if the single traits alone are not robust. For example it’s useless to add face recognition in a system that already has iris and fingerprint, since it would only lower the performance. An idea is to give more weight to the more robust traits in order to counterattack this.
Each biometric trait is processed individually, and a certain point in the process we can merge the obtained results.
There are other approaches of multibiometric system:
- Pure multimodal approach: combine the response of more biometric traits into a single decision;
- Multiple instances: give more than one instance of the same biometrict rait, but with a different object (different finger, different eye) before giving a result;
- Repeated instances: same as the multiple instances approach, but with the same object, for example same finger or same eye;
- Multiple algorithms: combining different prediction algorithms into a single response;
- Multiple sensors: combining different sensors to fuse the results into a single decision.
Different type of fusions
Fusion at Sensor Level
The fusion at sensor level is a very early fusion. It happens before the feature extraction. For example when more 2D images are fused into a single 3D model, and then the feature are extracted from the model.
This is difficult to achieve since most of the times we must have the same trait, and the kind of signal that is extracted must be the same.
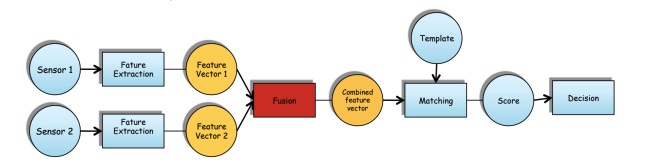
Fusion at Feature Level
In this case the fusion is between two extracted feature vectors. These could be for the same biometric trait or not. For example it’s possible to extract the features from the face with LBP, and do the same with the irises, and then combine the two obtained histograms.
The possible problems with this approach are:
-
The two feature vectors are not compatible, for example if one returns a wavelet coefficient and another one a histogram the fusion is not possible;
-
The feature vector fusion could generare a sparse space, and we may need a dimensionality reduction of overcome the curse of simensionality;
-
A more complex matcher may be required due to the augmented complexity of the feature vector;
-
Combined vectors may include noisy or redunant data.
How to do it:
It’s possible to fuse two feature vector by just concatenating them, or with more advanced techniques like SIFT.
Since the two feature vectors may have values that range in different scales, it may be a good idea to normalize them.
Another method is to build a new feature vector that contains not all the features in both the feature vectors, but just some of them, selected in a smart way, in order to not cause a too sparse final vector. For example we can maintain only the features in the interest points of both the images.
Another way is to combine the vectors in parallel, extending the shorted vector to the same lenght of the other one, and build the final vector as a combination of the twos.
Another way is to use Canonical Correlation Analysis, in order to find the pair of linear transformation in order to maximise the correlation coefficient between the features.
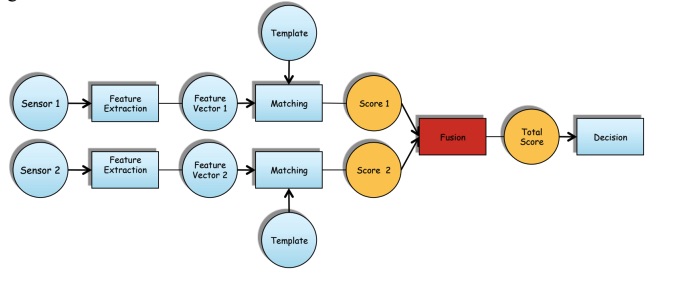
Fusion at Score Level
This is the most flexible and most popular approach.
In this case, each biometric trait is processed by a different subsystem, with a different algorithm and the fusion happens after matching, in this case the multiple scores are combined into a single score. The problem here is to find a good matching strategy.
From here, two different approaches can be taken:
- Transformation-based: the scores are first normalized and then are combined using fusion rules. This approach could be sensible to outliers and may be affected by not knowing exactly which is the minimum and maximum score that we can obtain.
- Classifier-based: Instead of trying to fuse the scores, we collect the scores into a new feature vector and then a classifier is trained with it.
Score level fusion rules
There are multiple rules that can be followed in order to fuse scores.
- Abstract: In case the classifier only returns the single class label that represent the response, and there isn’t any information about the rank or the score, what is possible to do is to get the label that’s been voted the most as final result.
- Rank: In case the classifier returns a raking of candidates. Ranking are converted in a sum of scores and the classifier with the highest score is selected. This method is called borda count.
-
Borda count example

-
- Measurement: In case the classifier returns the score that compares the pattern with each class, we can combine all the arrays by summing them, or getting the mean, or the product, or the max etc.
Fusion at Decision level
This is the last possible level of fusion, where the fusion happens after the decision of each single susystem that is responsible for the decision on a certain biometric trait.
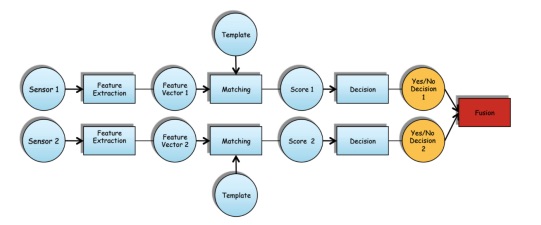
The simple fusion rule is to apply a logical combination on the results, by getting the AND (every classifier has to decide YES) or by getting the OR (the user is authenticated even if only one classifier outputs a YES).
Another fusion rule is by using major voting, so the final decision is the result voted by the majority of classifiers.