R-CNN is the first strong detector based on a neural network. The model works by taking in input an image and a set of regions proposed by a region proposal algorithm such as selective search. It then applies a detection CNN to each of those regions. The objects are classified with a SVM, and it use regression to move the bounding box accordingly.
If there are multiple regions that overlap the same object, during the detection the model chooses the region that best localize the object, by taking the one that has the largest score. This is because the assumption that an higher score means an higher probability of the object being in the region.
R-CNN modelled in this way is faster than previous approaches, but it’s still pretty slow, since we have to do 2000 (if ) independent forward passes for each image. The network is still not re-using the features that are shared between regions.
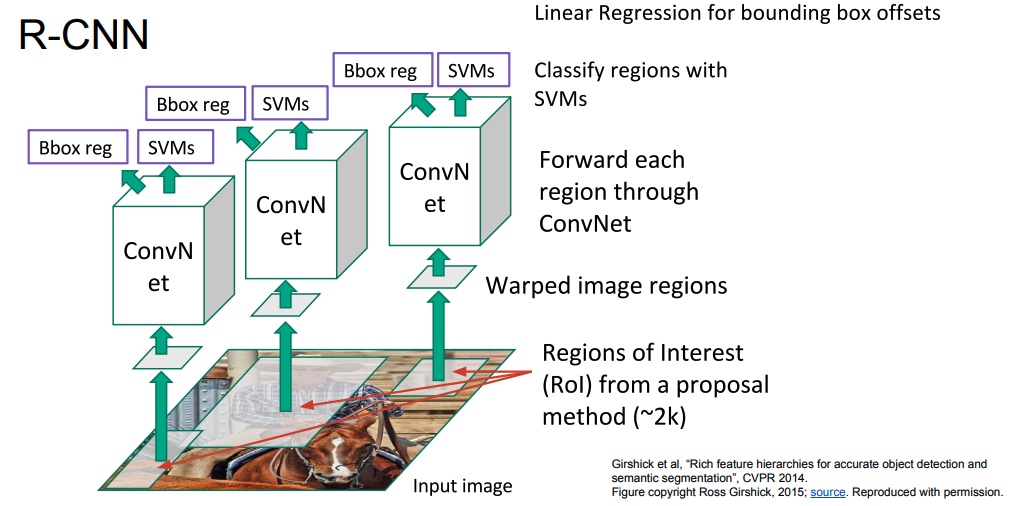
Note that since the CNN wants images of fixed size, and the region proposal are of different sizes, the regions will be warped before input into the CNN.
Also note the apart from all the possible classes on the dataset, the SVM also has a “Background” class that it will predict if no interested object is inside.