A multilayer perceptron (or deep feed-forward neural network) can be seen as a deep nested composition of functions, with a non-linear function (activation function) that produces the output of each single layer.
Note that the function composition operator is associative, so parentheses are not actually necessary.
denotes the activation functions. If we have just one layer with the logistic function, then we have the logistic regression model. In general the s will be different across the layers, and can be of various types.
A popular sigma is the ReLU (Rectifier Linear Unit) that is defined as
And note that this is a continuous function but it has a discontinuous gradient in the point , since on the left of that point the derivative is , and on the right is . So exactly in that point we have a singularity. This means that if the ReLU is present in any layers, the function will be non differentiable, and so we have to take care of it.
Hidden layers
Let’s rewrite the composition of functions , defined as:
Each set is the set of parameters of the -th layer. Each intermediate layer can be expressed as:
Where denotes the layer, is the matrix of weights (), is the input vector to the layer and is the bias. Sometimes the bias can be included inside the matrix, but in this case we must add a dimension full of s in the in order to match the shapes.
Neurons
Each row of the weight matrix is called a neuron or a hidden unit.
We can see the matrix multiplication as a collection of vector-to-scalar functions made in parallel, resulting in a new vector.
Single layer illustration
A single layer may be illustrated also with a graph where the first layer represents the components of , the second layer represents the output of the product , that is the linear combination between the vector and the -th row of . We can see that the neuron will be a fully connected with the inputs, this is a fully connected layer. (There will also be cases of non-fully connected layers)
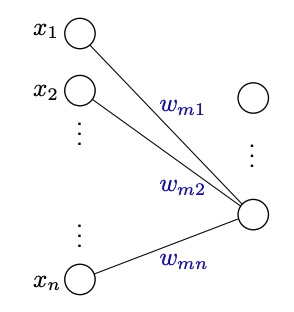
A graph of the fully connected layer
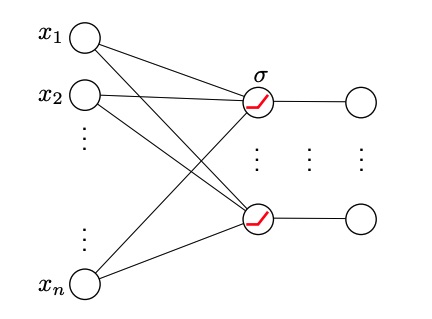
Adding the non-linear function
Output Layer
The output layer determines the co-domain of the network. For example if of the last layer in the network it’s the logistic sigmoid, then the entire network will map:
That might be a good idea in case of classification, but in a more general case it’s commont ot have a linear layer at the end of the network in order to map:
Universal Approximation Theorems
There is a class of theorems called Universal Approximation Theorems (UAT) which answers to the question: “What class of functions can we represent with a MLP?
One of the first ever theorems of this class, if not the first one, tells us that:
If is sigmoidal, then for any compact set , the space spanned by the functions is dense in for the uniform convergence. Thus, for any continuous function and any , there exists and weights s.t.:
Being dense in it means that if we take all linear combinations of , they allow to represent all the possible continuous functions in a -dimensional euclidean space.
Said that, the theorem tells us that we can approximate each continuous function with the desired accuracy using a MLP that has as few as just one layer. The larger is , the smaller can the error between the real function and the approximator be.
Note that taking linear combinations of all the means to just add a final linear layer.
There are also other UAT theorems that extends the universality for other s.
From this theorem we could think that a single hidden layer MLP is everything we need since it can approximise every existing continuous function, but we actually can’t. That’s because the theorem just says that those MLPs exist, but doesn’t tell us anything on how to do it.
MLP Training
Given a certain loss , solving for the weights is referred to as training.
In linear and logistic regression problems we’ve seen that the loss was always convex, but in general this isn’t the case. In fact the convexity of the loss comes from how is made. So if the neural network approximates a function that is very non-linear and very complex, the loss probably wouldn’t be convex, and so we cannot compute the gradient and set it to in order to minimize.
Also remember that we don’t want to find the global optimum, otherwise we will risk to overfit the training data.
Note also that the dimensionality of the gradient of is determined by the dimensionality of the output of .