Selective Search
When we’re building a region proposal algorithm, we don’t care about high precision (if the model propose a region, than it’s highly probable that there is an object inside), otherwise we wouldn’t need a detection CNN at all. What we’re interested in is an high recall (there is a low probability that a non proposed region contains an object), since if an object is not contained by at least one proposed region, the detection CNN will never detect that.
Since images are intrinsically hierarchical, detection at a single scale is not enough. Because of this, selective search works in the following way:
-
The image is over-segmented
-
We compute similarity measure between all adjacent region pairs and as
Where
This encourages small regions to merge early. Furthermore, we have
where and are color histograms, which encourage regions with similar colour to merge.
-
Merge two most similar regions based on the similarity measure
-
Go back to step 1 until the whole image is a single region.
-
Take the bounding boxes of all generated regions and treat them as possible object locations.
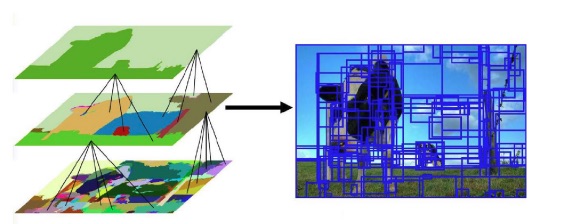

The number of region to propose is an hyperparameter that has to compromise efficiency with recall (and F1 score in general). I’m happy if the proposed region has an Intersection over Union of at least 0.5 with the ground truth bounding box. Recall is then computed as the proportion of objects that has .