Regularization is a mechanism that reduces overfitting, and so improves generalization.
Any modification that is intended to reduce the generalization error but not the training error can be considered as regularization.
Weight Penalties
The idea behind weight penalties is to add a regularizer, that is a function weighted by the factor , that increases the loss when the parameters don’t have certain properties.
controls the trade-off between data fidelitity (that is the part of the loss that directly involves the data) and the model complexity.
Tikhonov (or Ridge) regularization ()
In this case:
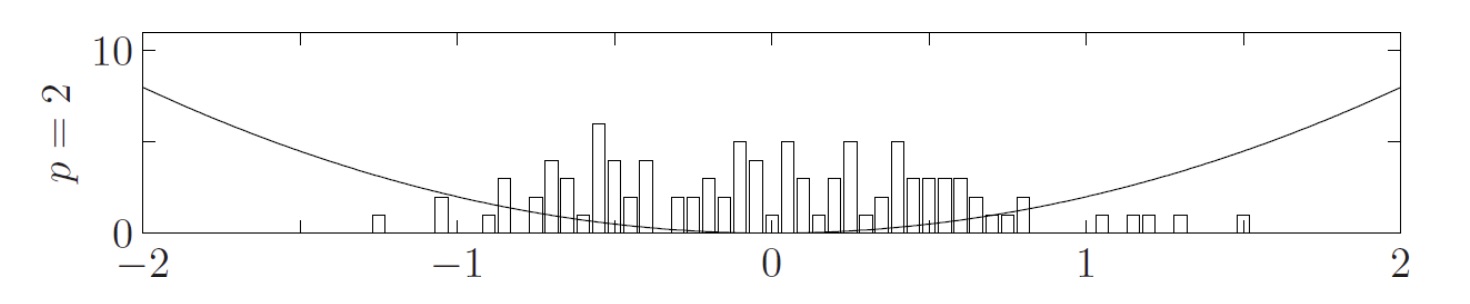
Each bin represent the amount of parameters having that particular value
This type of regularization promotes values for that are in the interval, and so promotes the shrinkage of the parameters .
This because all the that are not in that interval, when squared will result in a quadratically larger value, and so the loss will be incremented.
On the other hand, for values between and , the value squared will be smaller, and so the loss will be decremented, and the values promoted.
Lasso regularization ()
In this case:
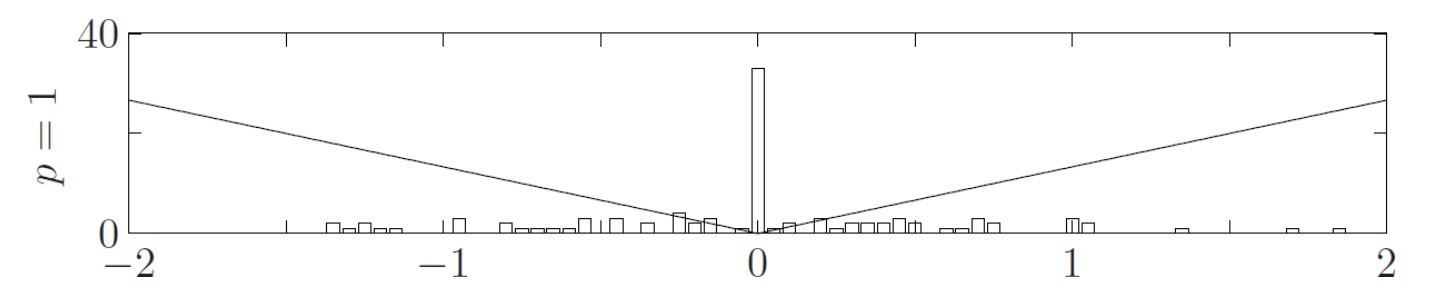
This type of regularization promotes sparsity, meaning that most of the parameters will be equal to .
This because differently from regularization, all the values will be discouraged in proportion with their value, so both numbers far from zero and near zero.
We can also use both and regularization, weighting one more than the other using and factors, in order to control the amount of sparsity in . This goes by the name of Elastic net regularization.
In general, we can also bound a type of regularization only to some specific layers.