As we said before, SIFT Descriptor was the state of art for more than 30 years before 2016. Even when CNNs were already introduced (AlexNET in 2012, the first real working CNN), SIFT always outperformed them.
What we want to do with deep learning is to replace SIFT and find some deep learning technique that outputs a global representation that would have the same local discriminative power, but that is more efficient.
The first deep learning approaches consisted in training a network such as CNN and use it to extract the features by taking the feature map before the fully connected layers. This is an approach yields compact representations and it’s fast at inference, but with many limitations. It also outperforms other global descriptors, but their performance is way below the state of the art.
First of all, the network is trained on datasets with generic classes, such as ImageNet, and so won’t work well with with some other classes.
Another limitation is the fact that neural networks such as CNN accept squared images of fixed size, which means that an image with a different aspect ration than squared will be distorted when resized. Most of the CNNs also use low resolution images.
A solution may be to fine-tune a pre-trained CNN on a dataset of landmarks images, but even if this is a crucial step to obtain better performances, another crucial step is also to use a good image representation (such as R-MAC) and a ranking loss instead of a classification loss.
R-MAC: Regional Maximum Activations of Convolutions
R-MAC is a fast model based on CNNs which solves the problems previously cited when using CNN global descriptors, such as the ration distortion and the low image resolution.
R-MAC is a modified version of MAC (Maximum activations of Convolutions). MAC is able to create a single dimensional vector as a descriptor for an image. Two images can then be compared with the cosine similarity between those descriptors.
The descriptor in MAC is computed as following:
-
Given an input image of size to a pre-trained CNN, we get as final activation map the tensor of size , where is the number of output feature channels. The spatial resolution depends on the CNN architecture and the input image size.
-
This 3D tensor is represented as a set of 2D feature where is the 2D tensor sliced on the -th channel, and is the response at a particular position .
-
The feature vector is then constructed by a spatial max-pooling over all location, formally given by:
The MAC algorithm produces a single feature vector that describes the whole image . The Regional-MAC considers instead only a rectangular region , and extracts the regional feature vector:
Now, the set of squared regions is defined on the CNN activation maps, and those are sampled at different scaled. The largest scale is , where the height and width of the region are equal to .
Each region is then preprocessed with normalization and PCA whitening (as seen in the revisited R-MAC below). The set of regions is then then summed and normalized again in order to produce a single feature vector for the entire image.
In the paper, the authors extend integral images in order to efficiently perform max-pooling over CNN activation maps.
Note
Integral images are a way of representing images in order to make the summation of different sub-regions very efficient.

R-MAC revisited
In the “Deep Image Retrieval: Learning global representations for image search” paper, the authors decide to revisit R-MAC making different important contributions, which allows the network to be trained end-to-end.
In particular, the first contribution they make is to use a three-stream Siamese network (with shared parameters between the streams) that uses a triplet ranking loss in order to optimize the weights of the R-MAC representation for the image retrieval task.
They use the public Landmarks dataset. Since the dataset was built by querying images with many search engines inputting names of different landmarks, it contains a very large amount of mislabeled and false positive images. Because of this, the authors proposed an automatic cleaning process which significantly improves the performances.
The second contribution they made consists in learning the pooling mechanism of R-MAC by using a region proposal network similar to the Faster R-CNN one. They also show that this approach outperform the rigid grid approach used in the original R-MAC implementation.
Representations of two different images can be compared using the dot-product. This methods outperforms all previous approaches and consolidates the sate of the art performances.
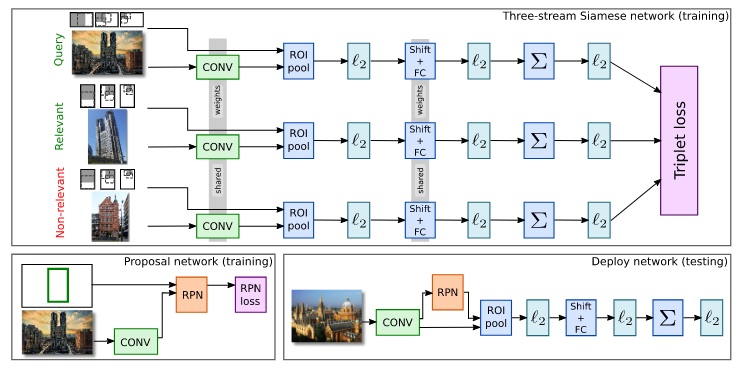
In particular, the network is trained in a contrastive-learning manner using three images:
- is the query image with a R-MAC descriptor
- is the relevant image with a descriptor
- is the non-relevant image with the descriptor
Each stream process the image in the following way:
- A pre-trained CNN (such as VGG16) is used to extract the activation maps from the images, which can be interpreted as local features that do not depend on the image size or aspect ratio.
- These activation maps are max-pooled in different regions of the image. Those regions are the output of the region proposal network.
- These pooled region features are independently normalized, whitened with PCA and normalized again. The resulting features are then summed and normalized again, producing a compact vector of usually or dimensions, which is independent of the number of regions in the image.
In order to make every operation differentiable, the PCA projection can be implemented with a shifting and a fully connected layer. In this way, the R-MAC representation can be computed in a single forward pass, and it’s possible to backpropagate through the network to learn the optimal weights of the convolutions and the projection.
The loss to minimize is the following ranking triplet loss:
where is a scalar that controls the margin.e