SimCLR is the first contrastive learning model that had competitive performances, proposed in 2020 in the paper A Simple Framework for Contrastive Learning of Visual Representations.
The pretext task proposed in the paper is the following:
-
For all the samples in the batch, do:
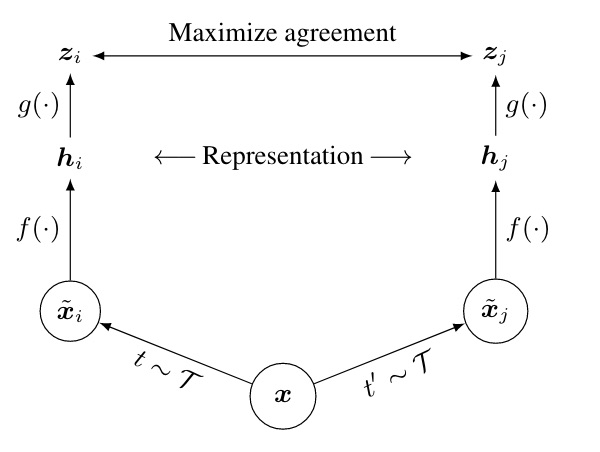
- From , it produces two augmented images using two transformations uniformally sampled from a transformation distribution.
- It encodes the two augmented samples with an encoder , which can be any neural network, and in the paper they use a simple ResNet.
- It feeds the representations into a projector (which in the paper is a simple MLP with a one layer) which will outputs the relative embeddings .
-
The objective is to maximise the cosine similarity between all the pairs if the two augmented images comes from the same image (positive pair), and minimize it if they come from different images (negative pair).
Note
Note that they augment two times each sample in the batch, so if the batch has size , the total datapoints will be , where are positive and are negative.

In order to fine-tune the model on the downstream task for classification(the one with the small dataset and labels) you only keep the encoder trained with the pretext task, and you add a single linear layer . The encode is freezed and the train only updates the final classification layer.
The results of the paper are amazing, since they were able to almost reach the supervised performances on ImageNet classification. The more the number of model parameters, the more accurate the classification will be, until it eventually will reach the supervised performances. This mean that we just need a bigger model, and so more resources, in order to train a model without having labels that will outperform the other supervised models.
In the paper they use a huge batch size of 4096, otherwise the model won’t ever see a diverse enough collection of negative samples. (Remember that the negatives are all the remaining samples inside of the batch size).
The key ingredients that made SimCLR so effective are:
- Augmentations, which are needed in order to create noised version of the same data to feed into the loss as a positive sample. In the paper they deeply studied which is the best set of augmentation to sample from, in order to increase the performances;
- Projection Head, which is essential to keep relevant information inside the representation space.
- Large batch size