We train the model using Gradient Descent-like algorithms. The bottleneck of the whole execution is computing the gradients of the loss .
Let’s evaluate the different solutions:
- Computing the gradients by hand will require an infeasible amount of time, and may produce some errors.
- We can use finite difference, meaning we compute an approximation of the derivative plugging in a very small number for the increment , line and then we compute the rate of change. This is a better solution, but it would require number of steps per datapoint, per iteration.
- We can create our custom software that takes a function an returns the symbolic expression that represent the derivative of that function, but also this would require the same amount of compuation steps as the solution before.
A better and efficient solution exists, and in order to explain that, we have to introduce computational graphs.
Computational Graph
Consider a generic function .
A computational graph is a directed acyclic graph (DAG) representing the computation of with intermediate steps that are stored in intermediate variables.
Let’s see what’s the computational graph of the function
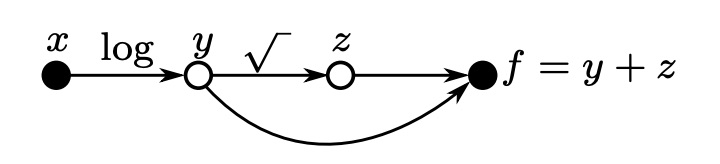
If you would write a program that solves that equation, you will store intermediate results (for example ) into a variable ( in the graph) in order to reuse it later. What’s a computational graph does is exactly the same things, keeping also track of what’s the variables that produced that specific result.
Let’s see another example for the function:

GIF animation of the computational graph

Final computational graph
We can evaluate by traversing the graph from the input to the output .
In PyTorch and other frameworks, the computational graph is constructed when we make the operations, like:
z = torch.sqrt(torch.sum(torch.pow(x, 2),1))The computational graph gets big very quickly for compelx and highly dimensional functions.
Automatic differentiation: Forward mode
We want to use the computational graph not only to evaluate , but also to evaluate the derivative , and w.r.t all the intermediate nodes (). We can do that by forward traversing the graph, and compute the derivatives using the other derivatives we compute along the way.
Let’s see how we can compute the by doing the forward-pass on the computational graph of the function .
The assumption we make is that each partial derivative is a primitive, that has a closed form solution and so can be computed on the fly. This is implemented using a lookup table ( cost for the look up) that maps each type of primitive derivative to its closed form solution in order to get the result efficiently.
If the input has only one dimension, than the cost of computing is the same as computing .
In general though, if the input has dimensions, the cost of computing has a multiply factor of , since we have to compute different derivatives w.r.t all the parameters ( ).
Automatic differentiation: Reverse mode
The solution to compute the gradient of in an efficient way that doesn’t depend on the input dimensionality is by traversing the graph in the reverse mode, meaning from the output to the input , computing all the derivatives of w.r.t. the inner nodes ().
Let’s again see how we can compute of the same function , but this time traversing the graph in the reverse order:

Reverse mode requires computing the values of the internal nodes first, which can be done by doiing a forward pass, in which we just evaluate the function and its inner node, but we don’t autodifferentiate. Once done that, we can do a backward pass in order to compute the derivatives of the output w.r.t. to each inner node and the input.
Forward mode vs Reverse mode computational cost
When we train neural networks, we’ll always have a loss function of the type:
That maps a dimensional vector to a scalar. Even if the output of the network has dimensions, the output of the loss function will always be a scalar.
In a general way, we can write the forward-mode autodifferentiation and the reverse-mode autodifferentiation in this way:
Let be the Jacobian (generalization of the gradient: matrix of partial derivatives) at layer , then:
-
Forward-mode autodiff**:**
The parenthesis in this case defines how we store the operation into a new variable. Each operation that is inside of parenthesis will be stored and then reused in the chain rule.
In this case (reading from right to left) since the first layer has a dimensionality of , this dimensionality will be carried throughtout all the computation, and so we need to a number of operations more or less equal to:
-
Reverse-mode autodiff:
In this case we start from the last layer, that we know being a scalar, so we will carry out through the computation only the single dimension, and so we need to compute a number of operations that don’t depend on the dimensionality of the input.