Useful Resources
When using Large Language Models (LLMs) implemented with the transformer architecture, there is a major problem: they are unidirectional, meaning that the representation is build from left to right (or from right to left). This is a problem since language understanding is bidirectional.
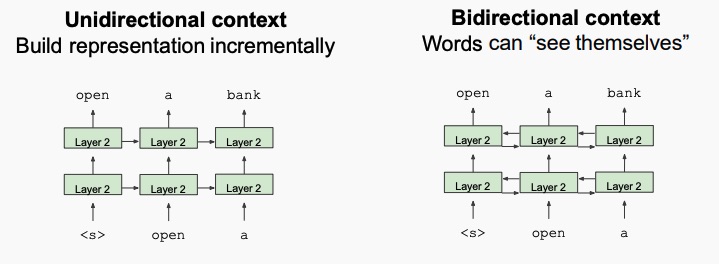
Before BERT, LLMs were unidirectional since this is mandatory in order to generate the probability distribution of the next word giving the previous words (context).
If the model is bidirectional, it’s not trivial how to train it, since all the words are available at all times, and because of that it’s not possible to let it predict the next word.
The idea behind the BERT (Bidirectional Encoder Representations from Transformers) family of language models, introduced in October 2018 by a group of researchers at Google, is to find a mechanism to train a bidirectional model.
BERT is a very useful tool since it can be pre-trained on a large corpus of text in order to understand the language, and then fine-tuned on a smaller dataset in order to learn a specific task, such as machine translation, question answering, text summarization or sentiment analysis.
Pre-training
BERT learns the meaning of a language by learning on two tasks simultaneously: predicting masked words and predicting if a sentence comes after another.
Masked Language Model
The solution they came up with is to mask some words while training, using a special token , and then let the model predict those words. The number of tokens to mask is a compromise between a too expensive training (if there is too little masking) and the right amount of context needed by the model to actually understand the context (too much masking).
In the paper, the authors chose to mask of the tokens.
Now, there is another problem: the is only used during training (not during fine-tuning nor testing), and so it’s never seen during inference, and that will degrade the model performances. In order to cope with that, during training each time a word has to be masked, the word is replaced with a random word of the times, or with the same word the other of the times. For the remaining of the times, the word is replaces with the token.
If BERT learns that a word doesn’t make sense in that place, it will replace it with the correct word.
Note
The loss only considers the masked words, and it ignores all other words.
Next Sentence Prediction
The second tasks that BERT learns is: given two sentences and , determine if the sentence follows the sentence .
The learning happens simultaneously because the input consists in two sentences, with some masked words. In the output, there is a special token which is the output of the binary classification of the Next Sentence Prediction task.
is another special token which separates the first sentence to the second.
BERT learns a contextual representation, meaning that two equal tokens will have a different embeddings if they are in two different contexts (tokens surrounding it).

Fine Tuning
During the fine-tuning, we can replace the fully connected layer at the end of the network with a custom fully connected layer, and train only that layer by freezing all the other BERT layers.
Note
While GPT architecture is made out of a stack of transformer decoders, BERT uses stacked transformer encoders.
Since BERT doesn’t learn to predict the next word, but only to reconstruct the input, how can it be used to predict the next word? Well it’s possible to do that by just fine-tuning the model, training it with a shift by in order to make it learn to predict the next word.
Input Embeddings
Let’s deep dive into how are the input embeddings generated.

- The token embeddings are generated using a pre-trained embedder, in the original paper implementation they use WordPieces embeddings, which have a vocabulary of 30K tokens. (All the embeddings are generated simultaneously and they have the same length).
- The segment embeddings is an encoding of the sentence number;
- The position embedding is an encoding of the token position.
The final token embedding is the sum of all those three vectors.
BERT Variations
There are some BERT variations which try to mitigate the problem causes by the fact that the token doesn’t appear at inference time.
RoBERTa
RoBERTa consists in BERT trained for more epochs and on more data. In the paper they conclude that more epochs alone help, but the performances are even better by training on more data.
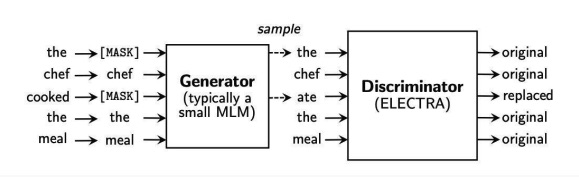
ELECTRA
This approach works by inserting a small language model as a generator, and a big language model as a discriminator. The big language model is called ELECTRA, and it learns to discriminate the original words from the replaced words by the small LM.
The approach is similar to the GAN. Since the task of knowing if a word was the original word or was replaces is harder than simply replacing the words, ELECTRA learns more information about the sentence.