AdaBoost is a boosted approach that can be used across every machine learning problem.
Boosting is a scheme that works by combining weak learners (linear classifiers) (Haar features in this case) into a strong one (non-linear classifier).
A weak classifier is a classifier that has a very low accuracy. The worst accuracy is 50%, since it has 50% probability of being right and 50% of being wrong, so it’s the same as just guessing.
In our case the classifiers have an output that’s in the set .
The strong classifier can be expressed as a combination of the weak ones.
Where:
- is the pattern to classify;
- are the weak classifiers;
- are the relative weights;
- is the normalization factor.
AdaBoost is a technique whose purpose is to learn the best sequece of weak classifiers ant their corresponding weights.
We define as the -th training pattern, and the ground truth associated with the pattern.
During learning we associate a distribution of weights to the patterns and ground truths . This distribution of weights is calculated and updated during the training.
At the start of the training all samples have the same weight, that can be initialized for example to one; after iteration , an higher weight is assigned to the patterns that have been more difficult to classify, in order for those pattern to get more attetion in the next iteration.
At the end of the process, the patterns can be classified by their weight: higher the weight, the more critical is the pattern.
-
Example of the computation of a strong classifier
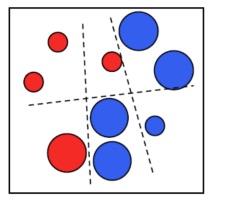
Let’s assume we have a two dimensional features. Each element could be in the blue or red class. We can see in the image how it couldn’t exist a line (weak classifier) that could perfectly divide blue dots from red dots.
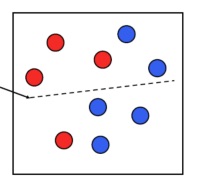
The samples that are misclassified, in this case the two blue dots over the line and the red dot under the line, will get an higher weigth in the next run.
In each step, the linear classifier aims to maximise the sum of correctly classified weights. The second classifier will divide the samples as the following
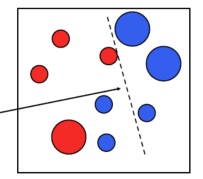
Once again, we increase the weight of the misclassified samples, we run the linear classification again and we’ll have this classification
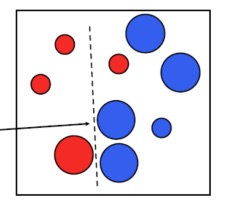
The final classifier (strong classifier) is the linear combination of the weak classifiers.