All activation function are used to introduce some non-linearity in the network, but depending on the network, some function are able to mitigate some other problems and make the learning process more stable.
Sigmoid
Sigmoid is the first activation function ever used. It was created to simulate the firing rate of a brain neuron.
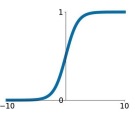
The function squashes the input into a range of .
The sigmoid has problems:
-
If we analyze the function, we can see that the function can kill the gradients if the input is not close to (positively or negatively). Because the gradient of the function w.r.t to si defined as:
This will produce the problem of vanishing gradients.
-
Another problem is the fact that the elements in the gradient vector have all the same sign, which is bad because we only can update the weights with all positive or all negative deltas. In practice this means that we can only “zig-zag” into the optimal path, which will result in a slower convergence. This isn’t really a big problem because of mini batches, and because this happens only for each sample, so we update with different signs for each sample.
-
The third problem is the fact that the exponential is a bit expensive in terms of computation complexity.
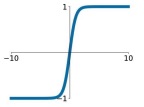
Tanh
Tanh is similar to the sigmoid and it resolves the two problems apart from vanishing gradients.
ReLU (and its variants)
Introduced with AlexNet, the Rectifier Linear Unit function solves a lot of problems.
First of all it doesn’t kill the gradients for positive s. It’s also very efficient and allows a faster convergence.
The two problems are that gradients are killed for negative s, and the fact that is not zero-centered like sigmoid or tanh. Here we will introduce some ReLU variants that aim to solve some of these problems:
- : doesn’t kill the gradients by introducing a small coeficient.
- : like the Leaky ReLU, but makes the coefficeint learnable.
- : Exponential Linear Unit, which is less efficient because of the exponential computation.
- : Scaled ELU, which is better for deep networks since it has a self-normalizing properties and so it doesn’t need Batch Norm.
Maxout
Maxout generalizes the ReLu and the Leaky ReLU by inserting two learnable linear layers, one in each side. Both the functions are linear, and there is no exponential. It doesn’t saturate nor die. The only problem is that it doubles the number of parameters (one network per side of the maxout).
Note
The rule of thumb is to use ReLU and see how it goes, then try to use one of its variants (including Maxout) to squeeze out some marginal gains. Don’t use sigmoid or tanh!