In machine learning, knowledge distillation or model distillation is the process of transferring knowledge from a large model to a smaller one. While large models (such as very deep neural networks or ensembles of many models) have higher knowledge capacity than small models, this capacity might not be fully utilized. It can be just as computationally expensive to evaluate a model even if it utilizes little of its knowledge capacity. Knowledge distillation transfers knowledge from a large model to a smaller model without loss of validity. As smaller models are less expensive to evaluate, they can be deployed on less powerful hardware (such as a mobile device). Knowledge distillation - Wikipedia
BERT and other pre-trained LLMs are extremely large and expensive to use. How are companies applying them to low-latency and highly used production services? The answer is distillation, also known as “model compression”.
The idea has been around for a long time, since the first papers about the subject dates back to 2006.
The idea is simple:
- You train the best and largest model, which is called the Teacher.
- You train a much smaller model called the Student which is trained to mimic the Teacher output. It learns using a large amount of input examples which are labelled by the Teacher.
This works well since the data generated and labelled by the Teacher is already cleaned and easier to learn for the Student.
This concept is similar to the Data++ concept, where you train a generator with some data, the you use this generator to re-generate the original data which will be cleaner (with less noise) in order to train another model.
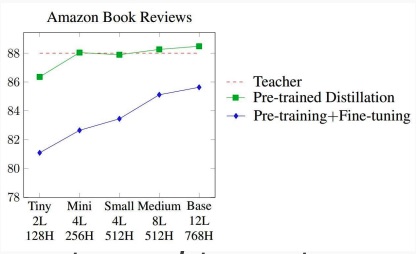
Distillation works much better than pre-training and fine-tuning on a more specific task, since it’s way faster at inference time.