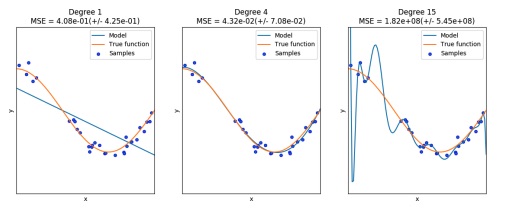
Underfitting - Just right fit - Overfitting
Overfitting and Undefitting are two phenomenons that may happen during the construction of the model that we want to avoid.
Underfitting (the image on the leftmost part) is when the model poorly fits the data, because of a too much generalization. We can notice that because we have a large MSE.
Overfitting (the image on the rightmost part) is when the model fits too well the training data, but isn’t able to generalize on different data. This translated on little or zero MSE error on the training data, but large error with different data. This also means that the model is “learning the noise”.
Generalization is an important concept in machine learning, and it means that the model performs well on data that is not part of the training set.
In order to see if the model is able to generalize, we should reserve some data for the “validation set”, that is a part of the data that we use to measure the error of the model. The important part is that the validation data, as well as the test data, is data that the model has never seen.
In general we can see if we’re building the model in a good way by following this path

Note on overfitting
Note that the number of parameters and overfitting are not directly correlated. Usually when a polynomial regression model has many parameters, it has the higher change to overfit, but this is not true for MLPs and other models.
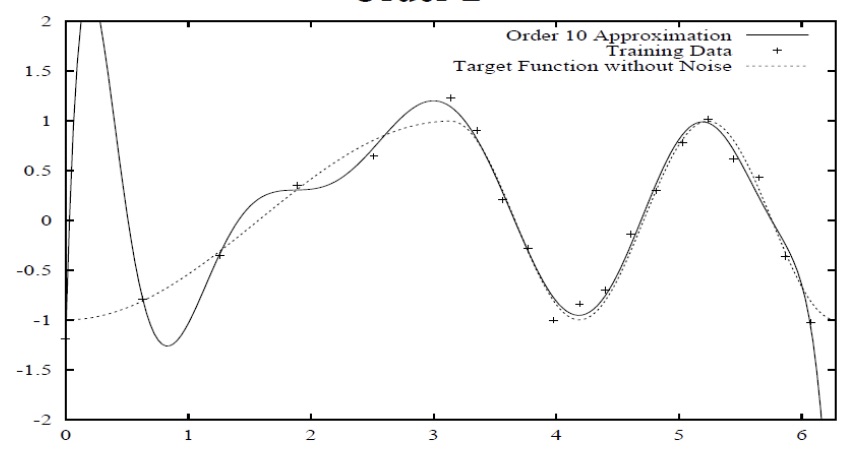
Overfitting is a local phenomenon. The model can overfit in some regions of the data, and fit right on other.