BYOL is a model that uses Contrastive Learning as a Self-Supervised Learning technique based on MoCo v2.
The idea behind BYOL is that you can learn everything without using the negative samples at all.
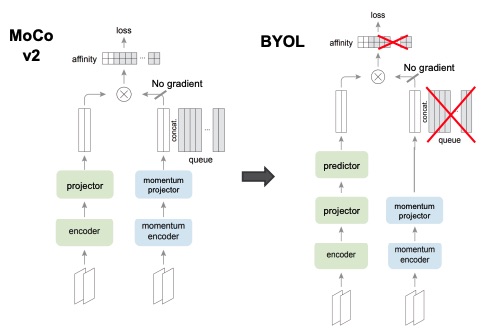
They do that by starting from the MoCo v2 architecture and removing the queue and negative samples from the loss. In order to make it work, they introduced a predictor module in the query branch.
In order to have a good representation, points that represent the same image should be close between them and far from the negative samples. If all the points are close together, it’s a bad representation.
Only removing the negatives mean only increasing the cosine similarity between the pair of samples, which means that all the points will collapse in a single point in the latent space. That’s why we need the negatives.
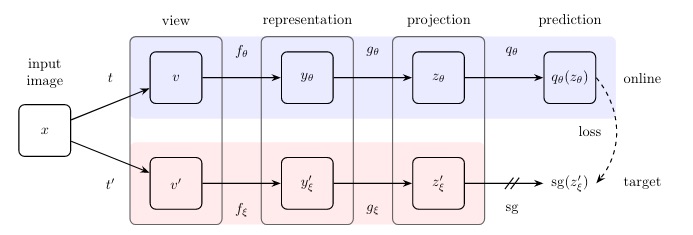
The predictor head and the momentum-updated encoder and projector is a key in order to avoid this collapse, this because now the architecture is asymmetric, and so the sample from the left and right branch will be different. Difference that is introduced by the predictor.