Object Detection
While segmentation is about classifying each pixel in an image, object detection is about detecting multiple instances of multiple object in an image, giving them a category and putting a bounding box around them.
Detection is hard because the objects can be small or occluded. Before deep learning the performances of the various algorithms were always kind of bad (around 40% of Mean Average Precision), while with the advent of Deep Learning the performances spiked out to 80%.
Object detection with just a fixed number of objects in an image can be seen as a Classification + Localization problem, meaning we have to classify the objects in the image but also find the coordinates of the bounding box.
We can treat the localization problem as a regression problem, meaning we can use the L2 loss for the bounding box coordinates, and then optimize the sum of the classification (optimized using cross entropy loss) and localization loss.
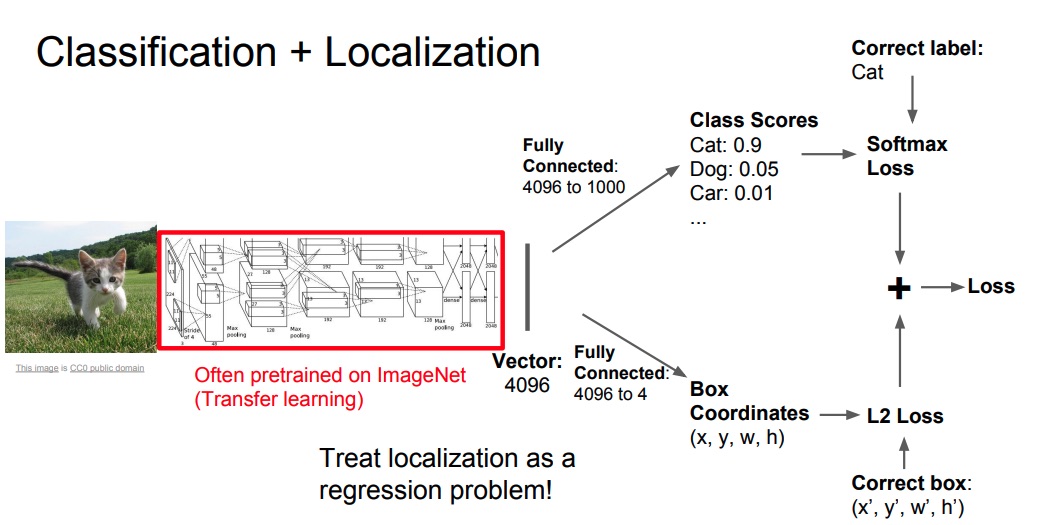
Because it’s a multi task loss, we need to insert a scaling factor in order to give one loss more importance over the other. This scaling factor is an hyperparameter.
This works for a single object detection, but what about multiple objects in the same image?
Note
This approach can be used also for pose estimation, where an image is input into a CNN and a set of coordinates, each for each joint, is used to compute different losses, which weighted average is then use to backpropagate.
Multiple Objects Detection
When we’re dealing with multiple objects in the same image we have some issues, since we are expecting a different number of outputs for each image with the same model, in particular one bounding box and one classification for each object in the image, which number is unknown before the detection, and for this reason we cannot apply the methods described above.
To solve this problem we can crop a random part of the image and apply a CNN to see if an object can be detected. We repeat this for each possible crop.
This is way too inefficient since the number of possible patches are a lot, and since we are not reusing the information we have already computed, for example if the two patches are overlapping.
Region Proposal
A solution to this problem is to run a lightweight algorithm on the image before the detection, which purpose is to output a set of proposed regions, meaning patches which may include an object. Then we can run the CNN only on those patches.
One kind of region proposal algorithm is Selective Search, which is able to propose 2K regions in a few seconds running on a CPU.
The detection model can not only tell if there is an object in the region or not, but since we are doing regression on the bounding box coordinates it can also move the bounding box in order to better localize the object.