Pose forecasting is the process of predicting the future frames, each one with a set of coordinates for joints, given an history of frames.
We can encode the joints (which is the spatial relations) with a MLP or a GCN. In case of a GCN, we will have a node for each joint, and an edge that connects the connected joints, and the same joints at across different frames (time steps). We can use then a decoder implemented with another GCN, CNN or TCN.
The adjacency matrix ( stands for spatial-temporal) will be of dimensionality where is the number of joints and is the number of time steps.
Regarding the temporal relations between poses, we can encode them using CNNs, LSTMs, GRUs or Transformer Networks. The encoder doesn’t differentiate between space and time.
The encoder is the most difficult part of the problem. We can use a simple TCN as a decoder.
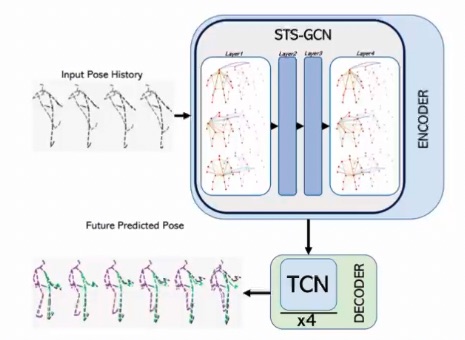
Since the model is predicting the future sequence, this is self-supervised (you split the sequence into train and validation).
Benchmark Pose Evaluation
The main datasets for training and benchmarking pose evaluation tasks are Human 3.6M, AMASS and 3DPW.