Note
Ensemble Learning is a technique in which different model are trained, and the final decision is just an aggregation of the decisions made by the single models. Ensemble methods are most of the time always more precise than a decision of a single model.
However, for deep nets this comes at a high computational cost.
The main idea behind dropout is to randomly drop some units in each layer (dropping means to set their value to ) and see if the result is better.
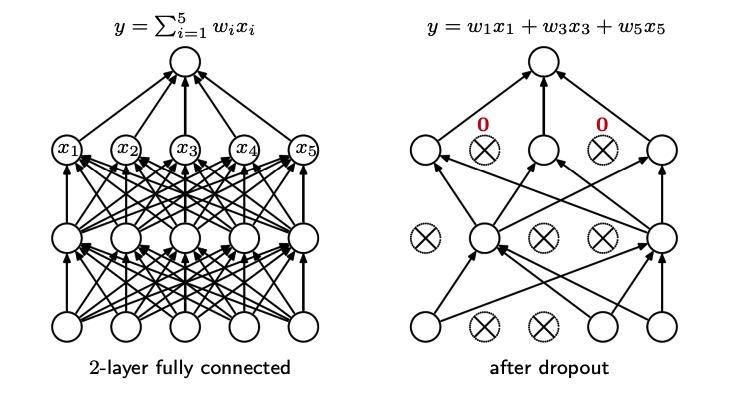
Note that this can be seen like an ensemble, because each time dropout is applied, we have a kind of different network, but the crucial part is that the weights are shared.
If there are nodes, we have possible ways to sample a different network (a network with some nodes dropped out), so exploring all the networks space is too costly.
To simplify, we drop out some nodes only when new training data is presented, for example at each mini-batch. We train the network just for one step, and then we apply dropout again.
Most of the time dropout is applied just before the non-linearity.
Testing
During testing, we should be able to average the trained weights from each model in the ensemble. The idea is to consider each weight that exits the node as where is the probability that the node has of staying in the network.
This works because if a node has probability of staying very low, then it was almost never present in the network, and so it’s contribution shouldn’t be considered so much, and so the weights will be decreased.
On the other hand, if is near the maximum value , the node contribution will be considered more, since it should be more important.
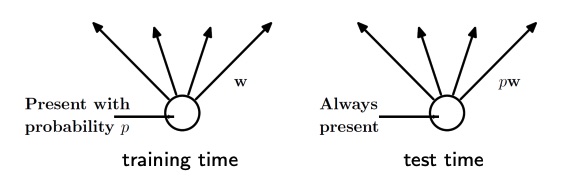
Note that is different at each layer.
If we don’t want to touch the weights at test time, we can divide the train weights by instead of multiplying the test weights by the same number. This is actually the recommended implementation of dropout. Dropout has two key features:
- Bagging: each model is trained on random data
- Weight sharing: the weights are shared between all the models, that is something that doesn’t happen in ensemble methods and that makes dropout efficient.
Some properties of dropout as a regularizer:
- Reduces co-adaptation (the phenomenon in which small errors in a unit are absorbed by another unit) by making units unreliable (with the weighting). This improves generalization to unseen data, hence reduces overfitting;
- The middle representation are sparse, meaning that the value after the activation function is sparse.
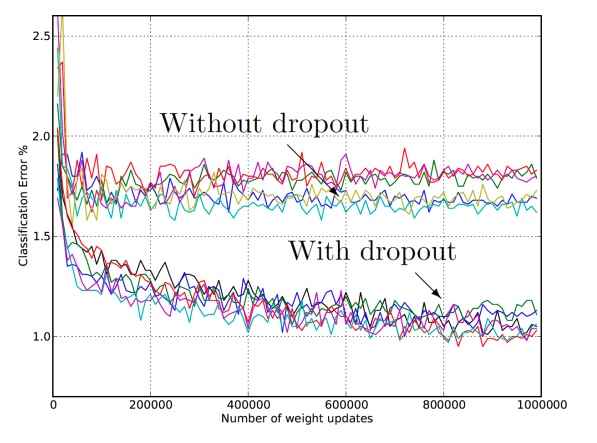
- Performs almost the same result as averaging all the models (this was proved experimenting).
- The training times are longer, since the parameter updates are noisier. The noise in the data is needed in order to improve generalization and avoid overfitting.
In conclusion, dropout is a simple and efficient way to improve the result of a neural network and reduce the overfitting.
Monte Carlo Dropout
Todo
To be added