Designing an efficient pretext task in a Self-Supervised Learning setting is hard, since the learned representations may not be as general as we which, but tied to a specific pretext task. In order to generalize more we can:
- Apply more than 1 transformation;
- Attract images of the same objects;
- Repel images of different objects.
The last two points are the key concept behind contrastive learning.
Let be the reference sample, the positive samples (the samples to attract) and the negative sample (the sample to repel), we want as objective the following relationship:
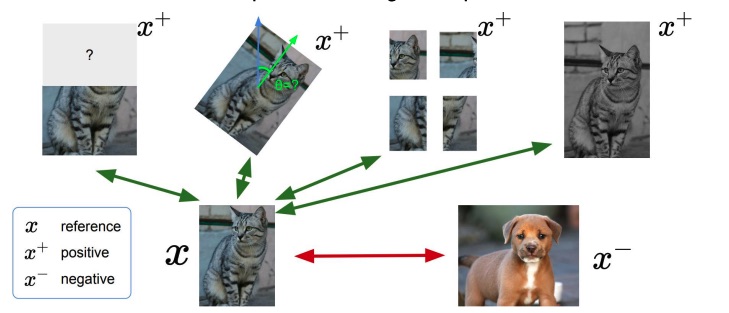
Which means to maximise the similarity between the original object and the augmented object, and minimize the similarity between the original object and the negative object.
The loss for contrastive learning is called InfoNCE loss, which is a variation of the Cross Entropy loss.

Ranking Loss
Unlike other loss functions, such as Cross-Entropy Loss or Mean Square Error Loss, whose objective is to learn to predict directly a label, a value, or a set or values given an input, the objective of Ranking Losses is to predict relative distances between inputs. This task if often called metric learning.
Ranking Losses functions are very flexible in terms of training data: We just need a similarity score between data points to use them. That score can be binary (similar / dissimilar). As an example, imagine a face verification dataset, where we know which face images belong to the same person (similar), and which not (dissimilar). Using a Ranking Loss function, we can train a CNN to infer if two face images belong to the same person or not.
To use a Ranking Loss function we first extract features from two (or three) input data points and get an embedded representation for each of them. Then, we define a metric function to measure the similarity between those representations, for instance euclidian distance. Finally, we train the feature extractors to produce similar representations for both inputs, in case the inputs are similar, or distant representations for the two inputs, in case they are dissimilar.
We don’t even care about the values of the representations, only about the distances between them. However, this training methodology has demonstrated to produce powerful representations for different tasks.
Examples of models that use Contrastive Learning
Examples of models that use Contrastive Learning are: