RNN is an architecture based on an internal state, which gets updated as the sequence is processed.
.jpeg)
The output is a function of not only the input but also of the recurrent module.
We can express the general formula for the RNN as:
In a more specific way:
And then we compute the output as:
Computational graphs
In the Vanilla RNN, the hidden state consists of a single vector.
Note that there is always just a single set of parameters for the entire sequence processing.
We can use RNNs for all the types of sequence problems we’ve seen so far.
Many to Many
.jpeg)
In the many-to-many case, at each step an output is produced and the loss is updated.
Many to One
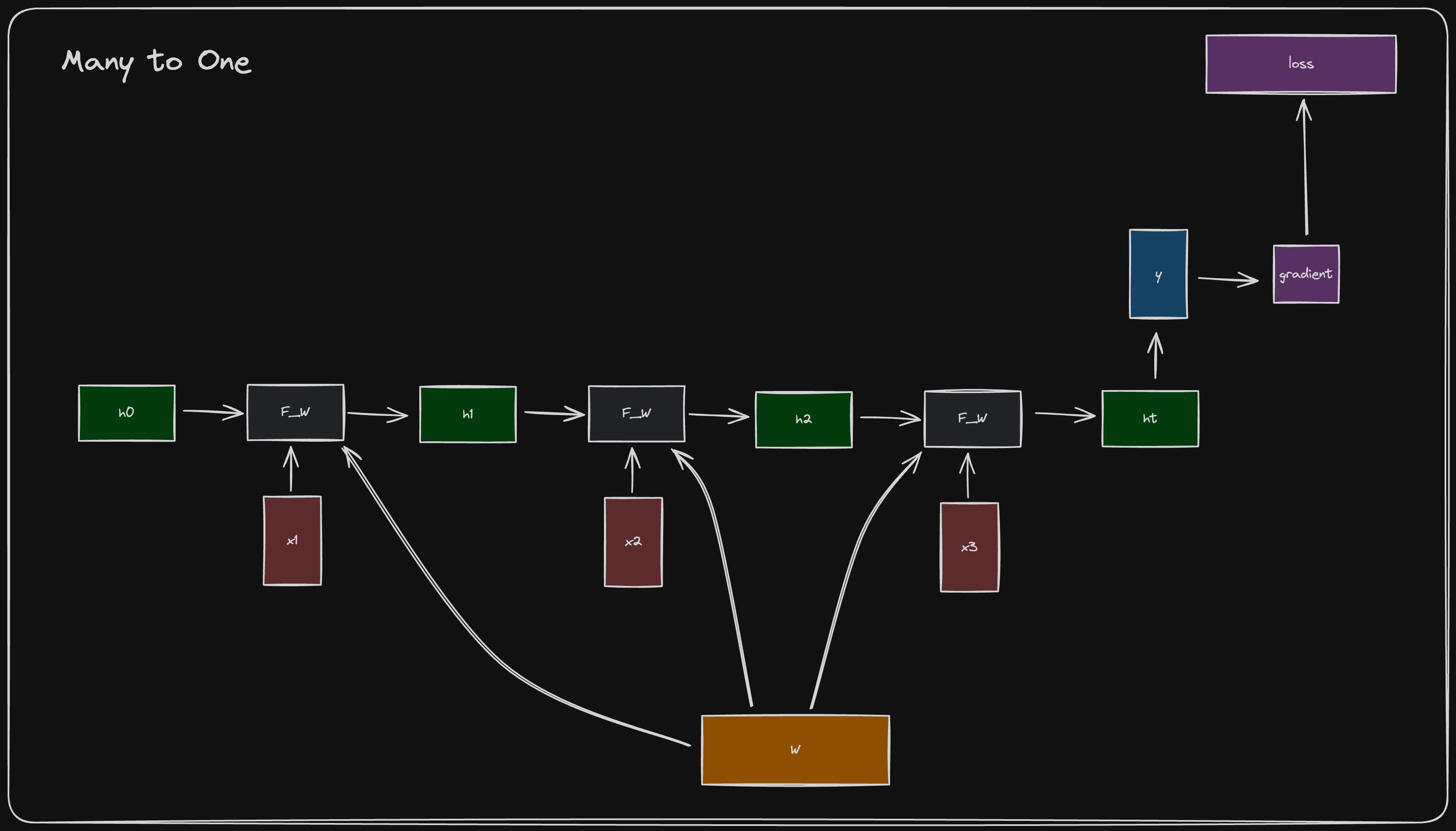
In the many-to-one case, just a single output is produced, and a single loss is computed at the end.
One to Many
.jpeg)
In the one-to-many case, we just have a single input . The problem is that we have to insert an input for all the other steps. Here we have two solutions:
- Just put a . This is not the best solution since we are putting some data that we invented.
- Put . This is a more reasonable solution and makes the RNN autoregressive, meaning the output at time step is given as input for the time step .
Many to One + One to Many
If we want to do a Many to Many, we can also first encode the input sequence in a single vector with a many-to-one RNN, then we take the single vector and produce a sequence as the output with a one-to-many RNN.
Example: Character-level Language Model Sampling
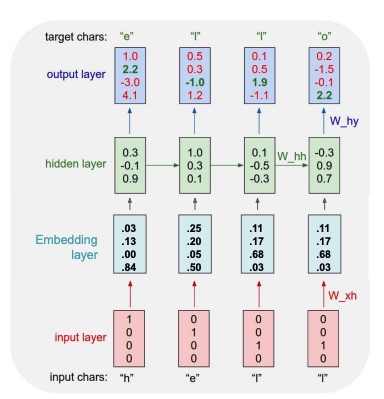
Most of the times the input goes first into an embedding layer, which produces an embedding, which then is passed to the hidden layer to produce an output. This is an autoregressive modelling, since each time we predict a new character from the current character and the current hidden state, and then feed the produces character to the next input.
Similarly for image, they can be embedded with the use of a CNN, which will produce a logits vector. We can then apply the RNN on the logits and perform our task (such as image captioning).
Note
Since the model tries to not be wrong, regarding image captioning it may produce some oversimplified captions such as “a picture of a cat”.
The past context is summarized inside of the hidden unit. If the context (past) is too long, the hidden state will begin to forget it, because it’s not as powerful. Transformers will be able mitigate this problem.
Ground Truth Forcing
Also known as “teacher forcing”, ground truth forcing consists in inputting computing the loss between the predicted token and the ground truth, and input the ground truth (instead of the model’s own prediction) in the next prediction step.
The main advantage of ground truth forcing is to make the learning process more stable, since if the model is trained with its own prediction, if a prediction at step is very wrong, the ones at step will be negatively affected. This doesn’t happen if we input the ground truth token.
This of course can be done only at train time, and at inference time the model predictions are given in input to the next steps.
Truncated backpropagation
We’ve seen how in a Vanilla many-to-many RNN each output contributes to the same loss, which becomes expensive fore long sequences, because of the many steps of chain rule that we have to apply.
A solution to this problem is truncated backpropagation, where the forward pass is done as usual, but the backpropagation is done only for a smaller number of steps in the past. This operation will produce a gradient for each segment. Note that the gradient refers to the same .
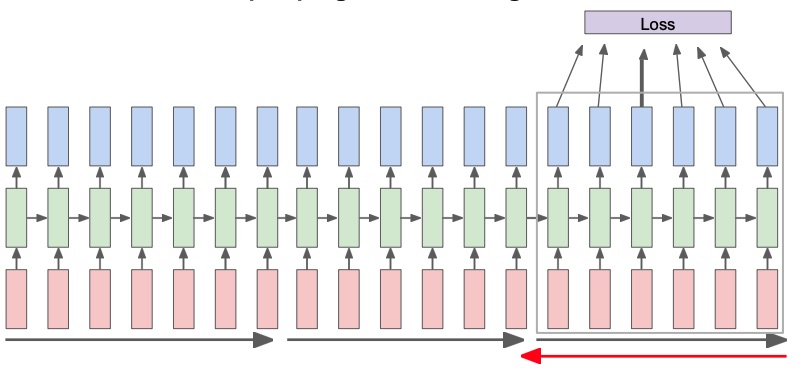
Multilayer RNNs
It’s possible to have multiple layers of a RNN
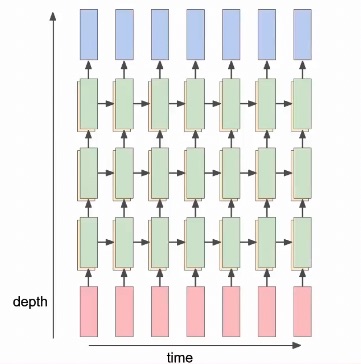
RNN Gradient Flow and long-term dependencies
Learning long-term dependencies with gradient gradient descent is difficult, because the gradient tends to vanish for long sequences. RNNs suffer from this phenomenon, let’s see why does this happen in detail.
In particular, we can see that the hidden at time is the result of:
This means that the backpropagation form to multiplies by .
The derivative is:
We also know that the derivative of the loss w.r.t. is the summation of the derivative of the loss at time wrt to :
If we’re considering the last of the losses () and the first , we can obtain the formula with the chain rule:
Note that
and sine , will be in the range , and so is always .
Because of this, if we have an higher , then will be closer and closer to , since we are multiplying by numerous factors in . This is the vanishing gradients problems, which causes the network to stop learning.
If we don’t use the , we will have a (where is the exponent of which we raise ). Here, if the largest singular value of the matrix is greater then , we get exploding gradients, otherwise we get vanishing gradients again, because of the matrix exponentiation.
We can clip the gradients (scale the gradient if its norm it’s bigger than a decided threshold) in order to avoid exploding gradients, but we need to modify the architecture in order to solve the vanishing gradient problem.
The most basing way of solving this is by using skip connections, in order for the network to not always backpropagate through .