The LSTM is an architecture based on the RNN, but with some modification on the hidden state in order to avoid the vanishing gradient problem for long contexts, as seen in RNNs. It aims to provide a short-term memory for RNN which can last thousands of timesteps.
The idea behind LSTM is to not use the same memory for both long term and short term relationships, but instead use only the short memory (predict the next output only based on a few timesteps back) and aggregate that with the long term memory (the whole timesteps from the beginning).
The RNN internal unit is replaced with the LSTM unit, which has four components, called gates:
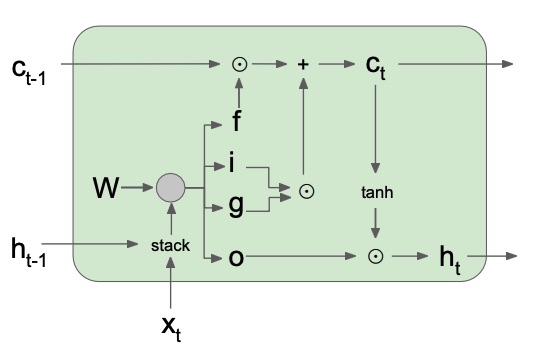
- Forget gate : since this multiplies the previous cell state , and it’s a number between and (because of the sigmoid activation function), it determines what is the percentage of the previous cell state that has to be remembered.
- Input gate : since this is multiplied with and added to the previous cell state , and it’s a number between and because of the sigmoid, it determines the percentage of the input signal that has to be put into the new cell state .
- Gate gate : squashed into an interval of by a function, since it’s then element-wise multiplied with the input gate , it determines how much of the input signal to pass to the next operation. Usually the gate gate is part of the input gate .
- Output gate : multiplied by the of the current , and squashed by the sigmoid function, it determines the percentage of the new that has to be passed to the output.
The cell state (where is the element-wise product) represent the short term memory.
The hidden state represents the long term memory.
Since the cell state isn’t affected by any trainable weights and biases, the gradient can flow directly from to and so it won’t vanish nor explode.
This uninterrupted gradient flow is similar to the identity mapping seen in the ResNet architecture. The idea behind is always the same: in order to not make the gradient vanish, just make skip connections.
Note
Since the LSTM reduces the vanishing gradient problem, but do not eliminate it (for long enough dependencies the gradient may still vanish), there are other variants of the LSTM (like GRU) which try to alleviate even more this problem, but none of them actually solves it completely.