When we generalize the idea behind the PCA as generative model, we call the projection and reconstruction procedures respectively encoding and decoding.
The encoder will be a function (neural net) that takes a data point in input and outputs a low-dimensional code that is the intermediate representation of .
The decoder will take the code and return the that is the most similar to the one that generated .
An architecture like this, in which encoder and decoder put together generate an output that is the most similar to the input. (If this doesn’t happen, then it’s just an encoder-decoder architecture).
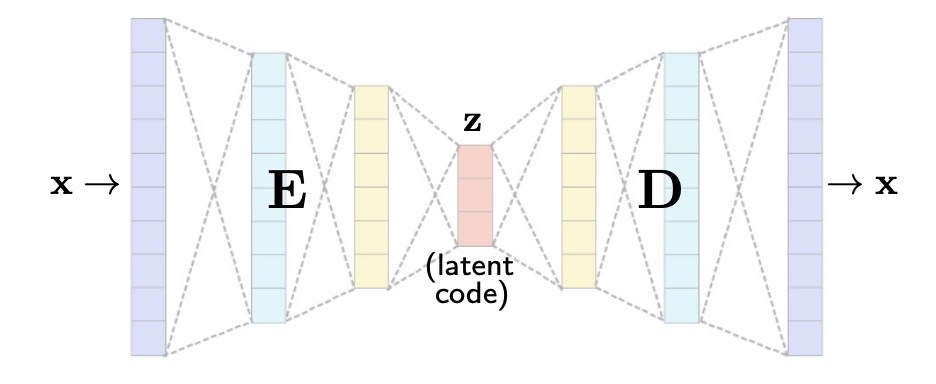
In order to enforce the Autoencoder to learn the encoder and decoder such that it will output a vector that is very similar to the input, we have to enforce it into the loss function:
The type of norm depends on the data, if we have data that lives in the euclidean space, than we can use the norm.
Importance of the bottleneck
The bottleneck in the architecture, meaning the fact that is important in order to avoid trivial solutions.
- If , then and so we risk that both the encoder and decoder will learn the identity function (meaning that )
- If , then we risk that the encoder and decoder will just create the as concatenated with as much needed in order to arrive to the dimensions.
Variational Autoencoders (VAE)
When dealing with simple autoencoders, we can have some regions of the space space in which the codes are immersed that have blanks, and so when we sample out of that blank and then decode the result, we won’t obtain an image that is natural. This because there aren’t enough points near that point.

The idea to resolve this problem is to enforce the latent space to be packed within a smaller area, and so to be dense, in order to avoid blanks.
Variational autoencoders are a type of autoencoders that allow to do that, in particular they allow to enforce a distribution in the latent space, meaning that it will produce codes that can be seen as samples from that probability distribution. In other words, if we sample the code from the latent space, then the sampling should respect the probability distribution that we enforced.
The distribution is chosen a priori, and most of the time it’ll be a Gaussian.
## Variational inferenceIn our scenario is a given data point and is a latent code.
In a variational autoencoder architecture, the encoder take in input a data point and returns the probability distribution of all possible latent codes.
The problem here is that we cannot exactly compute that, because we cannot compute:
Since we need to integrate over the entire latent space, which we don’t have. So the problem is intractable.
What we can do is to compute an approximation:
where is a neural net with weights . In order to let the neural net learn the best parameters we have to enforce the fact that we want the two distributions to be as close as possible in the loss function, by minimizing the divergence.
The contains the intractable term and so there still is a problem, but this is solvable noticing that, applying at theorem, the right part of the equation is always bigger than the left part, and so the maximisation of only the left part will approximate the maximisation of the whole thing.
The right part takes the name of Evidence variational Lower BOund or .
We are interested in finding:
The first part of this equation is simply the reconstruction loss, and we can also substitute it with the loss we’ve seen before.
The second term is the divergenge, and it’s needed in order to enforce the encoder to be the most similar to the true function , this is the regularizer.
Since we want to maximise that, it’s the same as minimizing the negative, so the loss is just:
Remember that the probability distribution is chosen a priori, so for example we choose , and so we can forget about the parameters , because the probability distribution has no free parameters.
The probabilistic encoder also generates a Gaussian distribution (if we choose the Normal distribution) with some mean and a standard variation , different for each data point (of course the output changes also according to the neural net parameters ).
The difference of a probabilistic encoder from a simple encoder is that it outputs the mean and the standard variation, from which we can sample each time a different , instead of outputting directly the .
The Gaussian is most of the time the best choice, also because using that the term has a closed form.