The idea to improve the model from the R-CNN is to swap the convolution and the cropping, by first convolving the images and the cropping directly the activation maps with the projected proposed regions. The task has still a combination of the two losses.
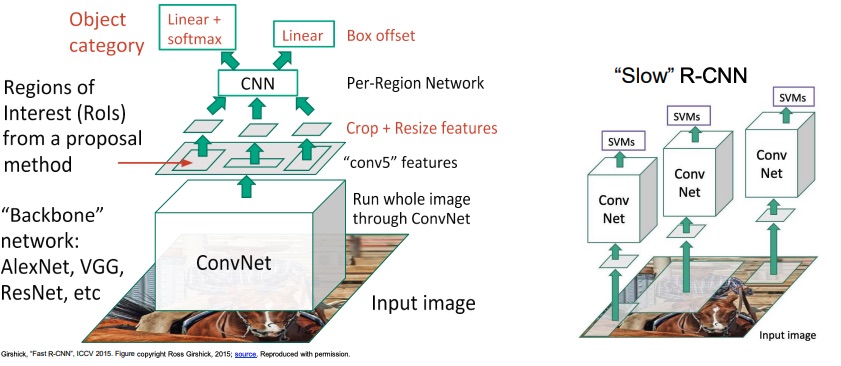
The problem now is how to achieve the projections of the proposed regions from the image to the activation map.
There are two fundamental ways of doing that:
-
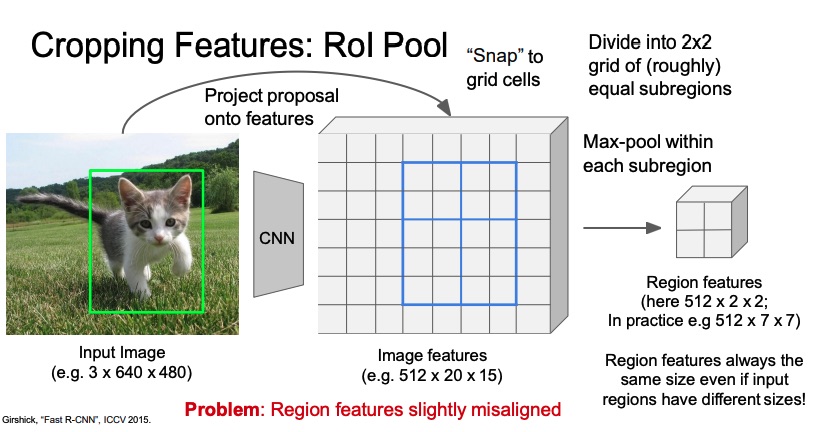
ROI Pool: I map the ROI from the image space to the activation map, I then “snap” the ROI to grid cells, meaning I have to round the decimal positions that come up when downscaling to the integer. Then I divide the grid into equal subregions and I apply max pooling within each subregion in order to finally have a region feature map. This last step is in order to have the image ready to be ingested into the final classification layers, since they expect a fixed size input. Max pooling is used instead of a simple resize since it’s differentiable. The problem with this solution is the fact that the “snapping” make the region features slightly misaligned. (Fast R-CNN actually uses this as mapping algorithm, but the problem has to be solved for Mask R-CNN).
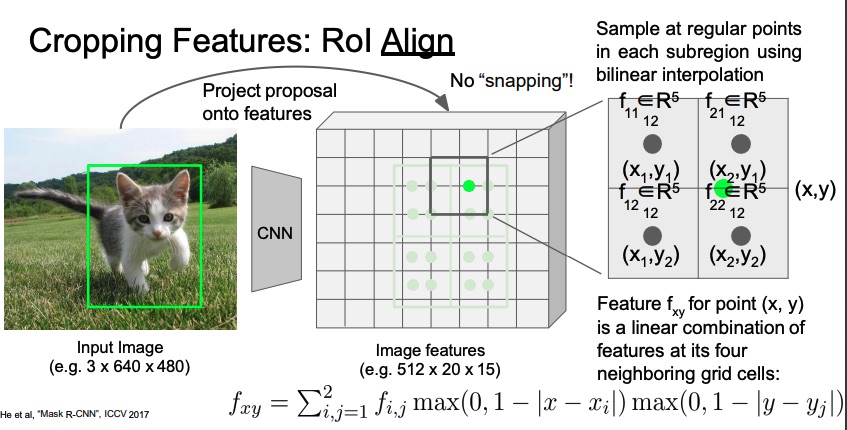
-
ROI Align: With ROI Align we don’t perform any “snapping”. On the other hand, we take each pixel at the exact position, and we assign to it the value computed as the average of the nearby pixels, component-wise weighted by their distance. For example if the green pixel is exactly in the middle, it will get of each feature from it neighbours. Done that, we go on with the max-pool within each subregion as we’ve done in the ROI Pool.