The first version of MoCo was released in parallel with SimCLR, while the second version was released a little later.
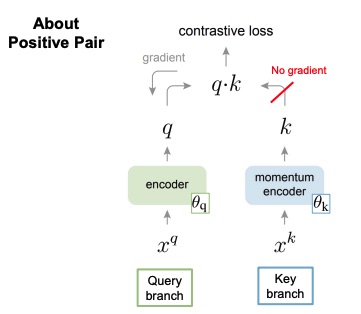
The key differences between MoCo v1 and SimCLR is the fact that the encoders between the left branch (query branch) and the right branch (key branch) are not the same:
In particular, regarding the positive pairs, only the query branch actually updates the encoder with backpropagation, while the key encoder is slowly updated trough the momentum update rule, which helps stabilizing the training.
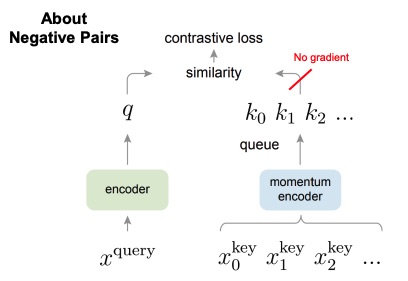
On the other hand, for what concerns the negative pairs, the only difference is not only the different encoder, but to not use a huge batch size like SimCLR, MoCo uses a running queue of keys, which are negative examples, which are updates with new key representation each time following the FIFO rule. This queue is used as negative examples.
With MoCo v2 they take the advantages from SimCLR and MoCo in order to build a better model.
From SIMCLR they take the non-linear projection head and the strong data augmentation, while from MoCo they take the queue of negatives and the momentum encoder and stop-gradient.